





一、MySQL软件简介
MHA Master Haproxy
MHA能够在较短的时间内实现自动故障检测和故障转移,通常在10-30秒以内;在复制框架中,MHA能
够很好地解决复制过程中的数据一致性问题,由于不需要在现有的replication中添加额外的服务器,仅
需要一个manager节点,而一个Manager能管理多套复制,所以能大大地节约服务器的数量;另外,安
装简单,无性能损耗,以及不需要修改现有的复制部署也是它的优势之处。
MHA还提供在线主库切换的功能,能够安全地切换当前运行的主库到一个新的主库中(通过将从库提升
为主库),大概0.5-2秒内即可完成。
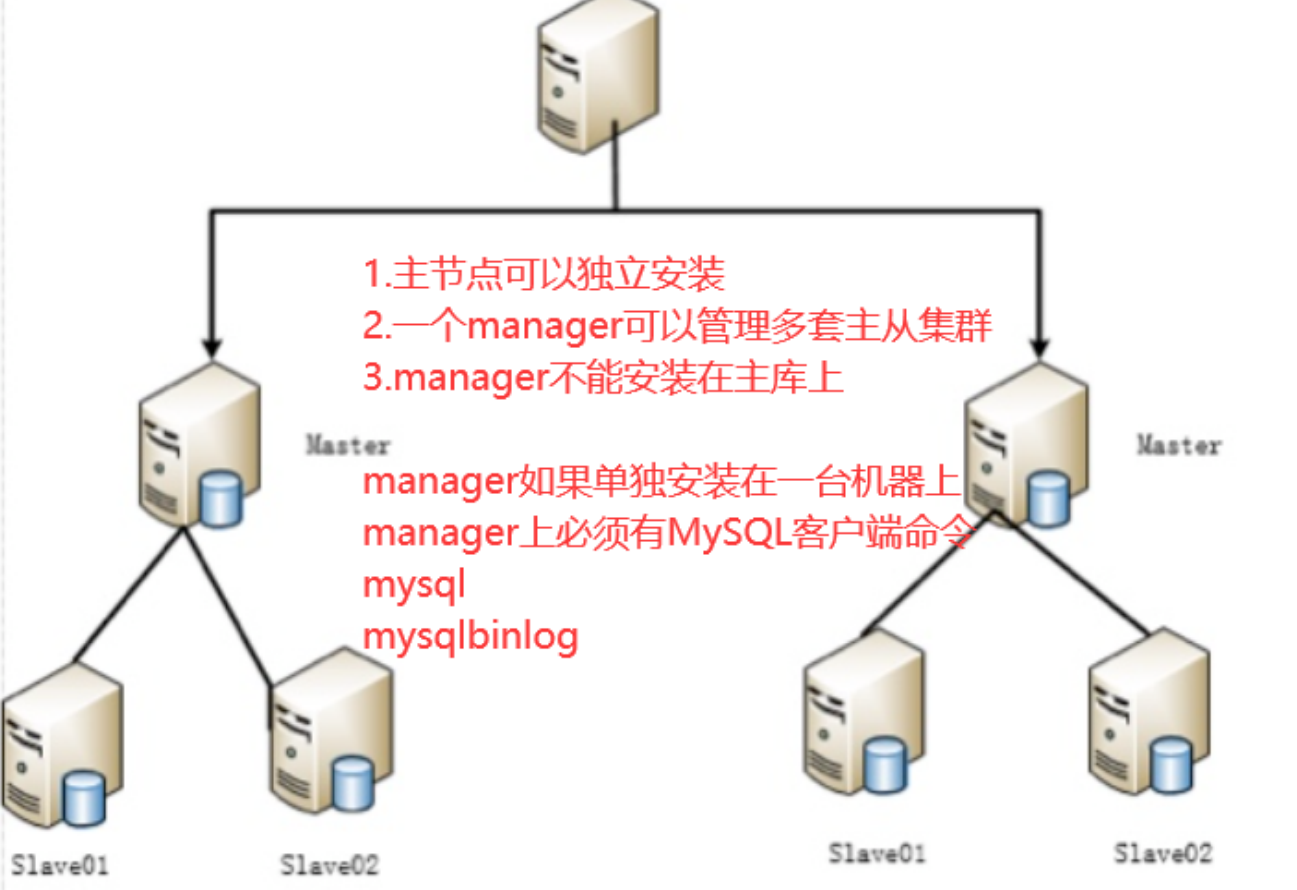
MHA由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以独
立部署在一台独立的机器上管理多个Master-Slave集群,也可以部署在一台Slave上
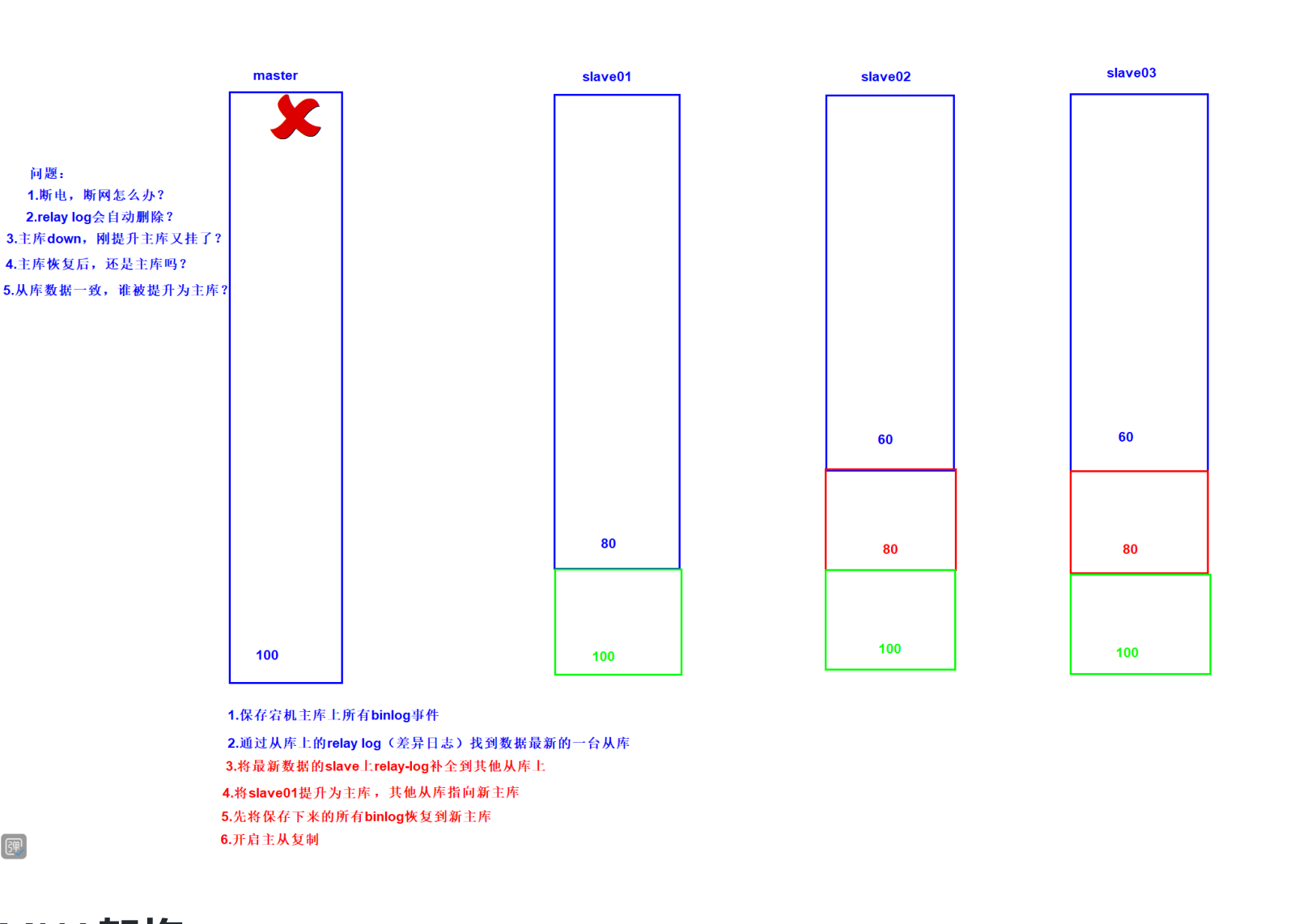
MHA工作原理:当Master出现故障时,它可以自动将最新数据的Slave提升为新的Master,然后将所有
其他的Slave重新指向新的Master。二.工作流程
1)把宕机的master二进制日志保存下来。
2)找到binlog位置点最新的slave。
3)在binlog位置点最新的slave上用relay log(差异日志)修复其它slave。
4)将宕机的master上保存下来的二进制日志恢复到含有最新位置点的slave上。
5)将含有最新位置点binlog所在的slave提升为master。
6)将其它slave重新指向新提升的master,并开启主从复制。
三.MHA架构图
主节点manager命令介绍:
masterha_check_repl // 检测主从复制,MHA启动的时候,需要对主从进行检测(可以手动)
masterha_check_ssh // 检测ssh免密,MHA manager一定要跟所有库都免密
masterha_check_status // 检测MHA启动状态的,systemctl status 服务名(手动)
masterha_conf_host // 配置主机,当主库宕机之后,将宕机主库配置,从配置文件中摘除
masterha_manager // 启动MHA(手动)systemctl start MHA
masterha_master_monitor // 检测主库心跳
masterha_master_switch // 做切换
masterha_secondary_check // 建立TCP连接
masterha_stop // 停止MHA systemctl stop MHANode节点命令介绍:
apply_diff_relay_logs // 2.对比relay log 找到数据最新的从库
filter_mysqlbinlog // 3.截取binlog,relay log
purge_relay_logs // 删除relay log(我们要关闭relay log 自动删除的功能),定期清理不用的relay log
save_binary_logs // 1.保存宕机主库上的所有binlog events四、MHA优点总结
1)自动故障转移快
2)主库崩溃不存在数据一致性问题
3)不需要对当前mysql环境做重大修改
4)不需要添加额外的服务器(仅一台manager就可管理上百个replication)
5)性能优秀,可工作在半同步复制和异步复制,当监控mysql状态时,仅需要每隔N秒向master发送ping
包(默认3秒),所以对性能无影响。你可以理解为MHA的性能和简单的主从复制框架性能一样。
6)只要replication支持的存储引擎,MHA都支持,不会局限于innodb五、MHA安装部署
环境准备:
| 主机名 | 外网 | 内网 | 角色 | 应用 |
|---|---|---|---|---|
| db01 | 10.0.0.51 | 172.16.1.51 | master | mysql、MHA-node |
| db02 | 10.0.0.52 | 172.16.1.52 | master | mysql、MHA-node |
| db03 | 10.0.0.53 | 172.16.1.53 | master | mysql、MHA-node |
| db04 | 10.0.0.54 | 172.16.1.54 | master | mysql、MHA-node、MHA-manager |
先决条件: //主从配置
1)主库和从库都要开启binlog
2)主库的server_id和从库不同,从库之间也不能相同
[root@db02 data]# vim /etc/my.cnf
[mysqld]
log-bin=mysql-bin
server_id=2
[root@db03 data]# vim /etc/my.cnf
[mysqld]
log-bin=mysql-bin
server_id=3
[root@db04 data]# vim /etc/my.cnf
[mysqld]
log-bin=mysql-bin
server_id=4
3)主库和从库都要用主从复制用户
# 主库创建:
root@localhost [(none)] >grant replication slave on *.* to rep@'172.16.1.%' identified by '123';
4)所有数据库之间免密
[root@db01 ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa >/dev/null 2>&1
[root@db02 ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa >/dev/null 2>&1
[root@db03 ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa >/dev/null 2>&1
[root@db04 ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa >/dev/null 2>&1
[root@db01 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.51
[root@db01 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.52
[root@db01 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.53
[root@db01 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.54
[root@db02 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.51
[root@db02 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.52
[root@db02 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.53
[root@db02 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.54
[root@db03 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.51
[root@db03 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.52
[root@db03 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.53
[root@db03 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.54
[root@db04 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.51
[root@db04 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.52
[root@db04 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.53
[root@db04 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.54
### 检测ssh
for i in 51 52 53 54;do ssh 172.16.1.$i "echo $i OK";done
5)所有库,要禁用自动删除relay log的功能
## 临时生效
root@localhost [(none)] >set global relay_log_purge = 0;
#永久生效 //修改配置文件
[root@db01 ~]# vim /etc/my.cnf
[mysqld]
relay_log_purge=0
6)从库只读(不能配置在配置文件中)
只有从库操作
set global read_only=1;
7)命令软链接
软链接mysql和mysqlbinlog
[root@db01 ~]# ln -s /app/mysql/bin/mysql /usr/bin/mysql
[root@db01 ~]# ln -s /app/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog
[root@db02 ~]# ln -s /app/mysql/bin/mysql /usr/bin/mysql
[root@db02 ~]# ln -s /app/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog
[root@db03 ~]# ln -s /app/mysql/bin/mysql /usr/bin/mysql
[root@db03 ~]# ln -s /app/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog
[root@db04 ~]# ln -s /app/mysql/bin/mysql /usr/bin/mysql
[root@db04 ~]# ln -s /app/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog安装node组件: //安装失败或者进度卡顿,中断多次尝试安装即可
[root@db01 ~]# yum localinstall -y mha4mysql-node-0.56-0.el6.noarch.rpm安装manager组件: //安装失败或者进度卡顿,中断多次尝试安装即可
[root@db04 ~]# yum localinstall -y mha4mysql-manager-0.56-0.el6.noarch.rpm配置MHA:
# 1.创建mha配置文件目录和日志目录
[root@db04 ~]# mkdir /etc/mha
[root@db04 ~]# mkdir /etc/mha/logs
# 2.创建MHA管理用户(所有库都要有,但是只要在主库创建,从库会同步)
root@localhost [(none)] >grant all on *.* to mha@'172.16.1.%' identified by 'mha';
# 3.创建mha配置文件
cat >/etc/mha/app1.cnf<<EOF
[server default]
manager_log=/etc/mha/logs/manager.log
manager_workdir=/etc/mha/app1
master_binlog_dir=/app/mysql/data
user=mha
password=mha
ping_interval=2
repl_password=123
repl_user=rep
ssh_user=root
ssh_port=22
[server1]
hostname=172.16.1.51
port=3306
[server2]
#candidate_master=1
#check_repl_delay=0
hostname=172.16.1.52
port=3306
[server3]
hostname=172.16.1.53
port=3306
[server4]
hostname=172.16.1.54
port=3306
EOF
# 4.检测ssh
[root@db04 ~]# masterha_check_ssh --conf=/etc/mha/app1.cnf
# 5.检测主从复制
[root@db04 ~]# masterha_check_repl --conf=/etc/mha/app1.cnf
# 6.启动mha
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /etc/mha/logs/manager.log 2>&1 &
[root@db04 ~]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:8140) is running(0:PING_OK), master:172.16.1.51六、MHA启动
# 机制:
1.MHA做完一次切换后,会自动结束进程
2.MHA做完一次切换后,会移除master配置
3.MHA做完一次切换后,会在工作目录下生成一个锁文件(8个小时) .lock .lck
#启动命令解析:
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /etc/mha/logs/manager.log 2>&1 &
nohup ## 后台运行
masterha_manager ## mha启动命令
--conf=/etc/mha/app1.cnf ## 指定配置文件
--remove_dead_master_conf ## 在配置文件中,移除宕机的master配置
--ignore_last_failover ## 忽略上一次故障转移
< /dev/null > /etc/mha/logs/manager.log 2>&1 &MHA日志分析
# 1.跳过gtid检测
GTID failover mode = 0
#报错:
master_ip_failover_script is not set. Skipping invalidating dead master IP address.
save_binary_logs \
--command=save \
--start_file=mysql-bin.000002 \
--start_pos=1024 \
--binlog_dir=/app/mysql/data \
--
output_file=/var/tmp/saved_master_binlog_from_172.16.1.51_3306_20230809184858.binlog \
--handle_raw_binlog=1 \
--disable_log_bin=0 \
--manager_version=0.56
# 3.保存binlog
先保存在宕机主库的/var/tmp下
然后scp到manager所在机器的mha工作目录下/etc/mha/app1
再从MHA机器上,发送到新的主库上/var/tmp
# 4.检测配置文件有没有 candidate_master=1
Candidate masters from the configuration file:
Non-candidate masters:
# 5.所有其他从库想要加进集群
CHANGE MASTER TO MASTER_HOST='172.16.1.52', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000002', MASTER_LOG_POS=154, MASTER_USER='rep', MASTER_PASSWORD='123';
## MHA切换优先级
1.candidate_master
2.数据量最新
3.配置文件中server标签值,越小,优先级越高
MHA集群恢复
# 1.修复宕机主库
systemctl start mysqld
# 2.找到change master语句
[root@db04 ~]# grep -i 'change master to' /etc/mha/logs/manager.log |awk -F: '{print
$4}'|sed "s#xxx#123#g"
# 3.在宕机主库中执行
# 4.开启主从复制
start slave;
# 5.修复 MHA 配置文件
# 6.启动MHA
[root@db04 ~]# nohup masterha_manager --conf=/etc/mha/app1.cnf --
remove_dead_master_conf --ignore_last_failover < /dev/null > /etc/mha/logs/manager.log2>&1 &
root@db04 ~]# vim recovery_mha.sh
#!/bin/bash
. /etc/init.d/functions
mha_log="/etc/mha/logs/manager.log"
down_master=$(sed -nr 's#^M.* (.*)\(.*\).*!$#\1#gp' ${mha_log})
pass="123"
mha_user=mha
mha_pass=mha
# 1.修复宕机主库
ssh $down_master "systemctl start mysqld"
while true;do
mysql_count=`ps -ef|grep -c [m]ysqld`
if [ $mysql_count -gt 0 ];then
action "$down_master MySQL Server" /bin/true
break
fi
done
# 2.找到change master语句
change=$(grep -i 'change master to' ${mha_log} |awk -F: '{print $4}'|sed "s#xxx#$pass#g")
# 3.在宕机主库中执行,开启主从复制
slave_de=`mysql -u${mha_user} -p${mha_pass} -h$down_master -e "show slave status\G"| wc -l`
if [ $slave_de -eq 0 ]
then
mysql -u${mha_user} -p${mha_pass} -h$down_master -e "${change};start slave;"&>/dev/null
fi
# 4.修复 MHA 配置文件
cat > /etc/mha/app1.cnf <<EOF
[server default]
manager_log=${mha_log}
manager_workdir=/etc/mha/app1
master_binlog_dir=/app/mysql/data
master_ip_failover_script=/etc/mha/app1/master_ip_failover.sh
password=${mha_user}
ping_interval=2
repl_password=${pass}
repl_user=rep
ssh_port=22
ssh_user=root
user=${mha_pass}
[server1]
hostname=172.16.1.51
port=3306
[server2]
hostname=172.16.1.52
port=3306
[server3]
hostname=172.16.1.53
port=3306
[server4]
hostname=172.16.1.54
port=3306
EOF七、MHA的VIP漂移(在云主机上,不支持vip漂移)
云主机的缺点:
- 不能添加ip地址
- 不能自定义路由
方式一:
1)MHA + keepalived
缺陷: - keepalived指定两台设备漂移,另一台必须提升为主库 (candidate_master)
- 如何确定另一台BACKUP数据一定最新 (半同步)
- 半同步会阻塞主库写入,影响主库性能,随时恢复到异步
-(不对外提供服务) - (提升半同步复制机器的配置)
方式二:
2)MHA自带vip脚本
手动将vip绑定到主库上
[root@db01 ~]# ifconfig eth1:1 172.16.1.55/24配置MHA识别master_ip_failover脚本
准备脚本:
[root@db04 mha]# cat app1/master_ip_failover.sh
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
my (
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
);
#根据情况定义VIP ip地址
my $vip = '172.16.1.55/24';
my $key = '1';
my $ssh_start_vip = "/sbin/ifconfig eth1:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig eth1:$key down";
GetOptions(
'command=s' => \$command,
'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
);
exit &main();
sub main {
print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host \n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
exit 0;
}
else {
&usage();
exit 1;
}
}
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
sub stop_vip() {
return 0 unless ($ssh_user);
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
# 1.修改配置文件 //定义vip脚本路径
[root@db04 ~]# vim /etc/mha/app1.cnf
[server default]
master_ip_failover_script=/etc/mha/app1/master_ip_failover.sh
# 2.授权
[root@db04 ~]# chmod +x /etc/mha/app1/master_ip_failover.sh
# 3.重启MHA //先停止在启动
[root@db04 ~]# masterha_stop --conf=/etc/mha/app1.cnf
#修改脚本格式
[root@db04 ~]# dos2unix /etc/mha/app1/master_ip_failover.sh
[root@db04 ~]# nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /etc/mha/logs/manager.log 2>&1 &
# 4.手动在主库上绑定VIP
[root@db01 ~]# ifconfig eth1:1 172.16.1.55/24
## 启用vip漂移脚本后导致MHA起不来的几种原因
1)脚本不在指定目录
2)没有执行权
3)格式问题 //报错127:0,一般少见
[root@db04 ~]# dos2unix /etc/mha/app1/master_ip_failover.sh
dos2unix: converting file /etc/mha/app1/master_ip_failover to Unix format ...
检测是否启动成功:
[root@db04 ~]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:18902) is running(0:PING_OK), master:172.16.1.51
#验证vip ip漂移
#停止db01主库
[root@db01 ~]# systemctl stop mysqld
#执行集群恢复脚本 // 参考前面文章
#查看新主库
[root@db02 ~]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:18902) is running(0:PING_OK), master:172.16.1.52
#新主库查看是否有vip ip
[root@db02 ~]# ip a | grep eth1
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 172.16.1.52/24 brd 172.16.1.255 scope global eth1
inet 172.16.1.55/24 brd 172.16.1.255 scope global secondary eth1:1
#mha在第一次主库故障漂移后,会自动停止,需手动重新启动,
方可在第二次新主库故障时才会自动漂移 在第二次启动MHA的时候切记一定修复集群方可启动解决binlog因为断电断网无法保存
#可以使用mysql自带的命令mysqlbinlog实现
## binlog server是MySQL集群内的某一台机器
[server1]
hostname=172.16.1.51
port=3306
[server2]
hostname=172.16.1.52
port=3306
[server3]
hostname=172.16.1.53
port=3306
[server4]
hostname=172.16.1.54
port=3306
[binlog1]
no_master=1 //永不提升为主库
master_binlog_dir=/data/mysql/binlog
hostname=172.16.1.54
## binlog server是MySQL集群外的某一台机器
[server1]
hostname=172.16.1.51
port=3306
[server2]
hostname=172.16.1.52
port=3306
[server3]
hostname=172.16.1.53
port=3306
[server4]
hostname=172.16.1.54
port=3306
[binlog1]
master_binlog_dir=/data/mysql/binlog
hostname=172.16.1.58
## 创建binlog存放目录
mkdir -p /data/mysql/binlog
[root@db04 binlog]# mysqlbinlog -R --host=172.16.1.55 --user=mha --password=mha --raw--stop-never mysql-bin.000001 &1)sersync + rsync
问题:MHA怎么知道,你binlog在哪?
[binlog1]
master_binlog_dir=/data/mysql/binlog
hostname=172.16.1.542)mysqlbinlog
- 查看binlog --base64-output=decode-rows
- 截取binlog --start-position --stop-position
- 同步binlog
七、MySQL读写分离
工具:
- mysql-proxy Lua
- atlas 360:C Alibaba:Java
- mycat
推荐使用:Atlas
Atlas主要功能
1.读写分离
2.从库负载均衡
3.IP过滤
4.自动分表(不用)
5.DBA可平滑上下线DB
6.自动摘除宕机的DB
分表功能:
- 垂直拆分
- 水平拆分
Atlas相对于官方MySQL-Proxy的优势:
1.将主流程中所有Lua代码用C重写,Lua仅用于管理接口
2.重写网络模型、线程模型
3.实现了真正意义上的连接池
4.优化了锁机制,性能提高数十倍
八、Atlas安装
#下载安装
[root@db01 ~]# wget https://github.com/Qihoo360/Atlas/releases/download/2.2.1/Atlas-2.2.1.el6.x86_64.rpm
[root@db01 ~]# rpm -ivh Atlas-2.2.1.el6.x86_64.rpm
## 修改配置文件
[root@db01 ~]# vim /usr/local/mysql-proxy/conf/test.cnf
[mysql-proxy]
#带#号的为非必需的配置项目
#管理接口的用户名
admin-username = user
#管理接口的密码
admin-password = pwd
#Atlas后端连接的MySQL主库的IP和端口,可设置多项,用逗号分隔
proxy-backend-addresses = 172.16.1.55:3306
#Atlas后端连接的MySQL从库的IP和端口,@后面的数字代表权重,用来作负载均衡,若省略则默认为1,
可设置多项,用逗号分隔
proxy-read-only-backend-addresses = 172.16.1.52:3306,172.16.1.53:3306,172.16.1.54:3306
#用户名与其对应的加密过的MySQL密码,密码使用PREFIX/bin目录下的加密程序encrypt加密,下行的
user1和user2为示例,将其替换为你的MySQL的用户名和加密密码!
pwds = rep:3yb5jEku5h4=, mha:O2jBXONX098=
#设置Atlas的运行方式,设为true时为守护进程方式,设为false时为前台方式,一般开发调试时设为
false,线上运行时设为true,true后面不能有空格。
daemon = true
#设置Atlas的运行方式,设为true时Atlas会启动两个进程,一个为monitor,一个为worker,monitor
在worker意外退出后会自动将其重启,设为false时只有worker,没有monitor,一般开发调试时设为
false,线上运行时设为true,true后面不能有空格。
keepalive = true
#工作线程数,对Atlas的性能有很大影响,可根据情况适当设置,CPU核心数
event-threads = 1
#日志级别,分为message、warning、critical、error、debug五个级别
log-level = error
#日志存放的路径
log-path = /usr/local/mysql-proxy/log
#SQL日志的开关,可设置为OFF、ON、REALTIME,OFF代表不记录SQL日志,ON代表记录SQL日志,
REALTIME代表记录SQL日志且实时写入磁盘,默认为OFF
sql-log = ON
#慢日志输出设置。当设置了该参数时,则日志只输出执行时间超过sql-log-slow(单位:ms)的日志记
录。不设置该参数则输出全部日志。
sql-log-slow = 10
#实例名称,用于同一台机器上多个Atlas实例间的区分 //实例名称必须和配置文件名一样
instance = test
#Atlas监听的工作接口IP和端口
proxy-address = 0.0.0.0:3307
#Atlas监听的管理接口IP和端口
admin-address = 0.0.0.0:2345
#分表设置,此例中person为库名,mt为表名,id为分表字段,3为子表数量,可设置多项,以逗号分
隔,若不分表则不需要设置该项
#tables = world.city.countycode.5
#默认字符集,设置该项后客户端不再需要执行SET NAMES语句
charset = utf8
#允许连接Atlas的客户端的IP,可以是精确IP,也可以是IP段,以逗号分隔,若不设置该项则允许所有
IP连接,否则只允许列表中的IP连接
client-ips = 127.0.0.1,172.16.1
#Atlas前面挂接的LVS的物理网卡的IP(注意不是虚IP),若有LVS且设置了client-ips则此项必须设置,
否则可以不设置
#lvs-ips = 192.168.1.1
#启动
[root@db01 conf]# /usr/local/mysql-proxy/bin/mysql-proxyd lol start
OK: MySQL-Proxy of lol is started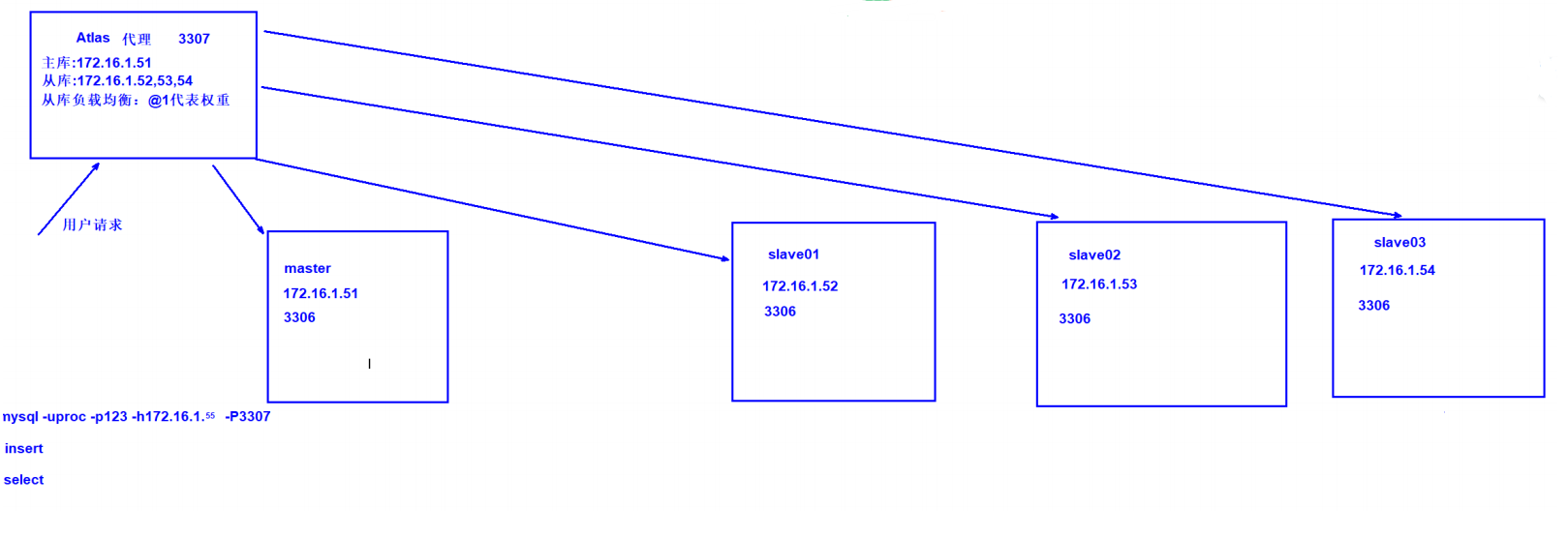
Atlas管理接口使用
## 管理接口
#管理接口的用户名
admin-username = user
#管理接口的密码
admin-password = pwd
#Atlas监听的管理接口IP和端口
admin-address = 0.0.0.0:2345
[root@db01 ~]# mysql -uuser -ppwd -h127.0.0.1 -P2345
#查看帮助
user@127.0.0.1 [(none)] >SELECT * FROM help;
+----------------------------+---------------------------------------------------------+
| command | description |
+----------------------------+---------------------------------------------------------+
| SELECT * FROM help | 查看帮助 |
| SELECT * FROM backends | 查看后端状态 |
| SET OFFLINE $backend_id | set offline 3; 下线指定的数据库 |
| SET ONLINE $backend_id | set online 3; 上线指定的数据库 |
| ADD MASTER $backend | add master 127.0.0.1:3306 添加一个主库 |
| ADD SLAVE $backend | add slave 172.6.1.59:3306 添加一个从库 |
| REMOVE BACKEND $backend_id | 摘除后端指定的数据库 |
| SELECT * FROM clients | 查看后端可以连接的客户端 |
| ADD CLIENT $client | example: "add client 192.168.1.2", ... |
| REMOVE CLIENT $client | example: "remove client 192.168.1.2", ... |
| SELECT * FROM pwds | 查看atlas允许连接的用户 |
| ADD PWD $pwd | 添加一个用户,密码写明文即可 |
| ADD ENPWD $pwd | 添加一个用户,密码必须先加密再添加 |
| REMOVE PWD $pwd | 删除一个用户 |
| SAVE CONFIG | 保存配置文件 |
| SELECT VERSION | 查看版本 |
+----------------------------+---------------------------------------------------------+
#查看用户密码
user@127.0.0.1 [(none)] >SELECT * FROM pwds;
+----------+--------------+
| username | password |
+----------+--------------+
| rep | 3yb5jEku5h4= |
| mha | O2jBXONX098= |
+----------+--------------+
#查看数据库主机池
user@127.0.0.1 [(none)] >select * from backends;
+-------------+------------------+-------+------+
| backend_ndx | address | state | type |
+-------------+------------------+-------+------+
| 1 | 172.16.1.55:3306 | up | rw |
| 2 | 172.16.1.52:3306 | up | ro |
| 3 | 172.16.1.53:3306 | up | ro |
| 4 | 172.16.1.54:3306 | up | ro |
+-------------+------------------+-------+------+
user@127.0.0.1 [(none)] >set offline 3;
+-------------+------------------+---------+------+
| backend_ndx | address | state | type |
+-------------+------------------+---------+------+
| 3 | 172.16.1.53:3306 | offline | ro |
+-------------+------------------+---------+------+
1 row in set (0.00 sec)
user@127.0.0.1 [(none)] >select * from backends;
+-------------+------------------+---------+------+
| backend_ndx | address | state | type |
+-------------+------------------+---------+------+
| 1 | 172.16.1.55:3306 | up | rw |
| 2 | 172.16.1.52:3306 | up | ro |
| 3 | 172.16.1.53:3306 | offline | ro |
| 4 | 172.16.1.54:3306 | up | ro |
+-------------+------------------+---------+------+
user@127.0.0.1 [(none)] >set online 3;
+-------------+------------------+---------+------+
| backend_ndx | address | state | type |
+-------------+------------------+---------+------+
| 3 | 172.16.1.53:3306 | unknown | ro |
+-------------+------------------+---------+------+
1 row in set (0.00 sec)
user@127.0.0.1 [(none)] >select * from backends;
+-------------+------------------+-------+------+
| backend_ndx | address | state | type |
+-------------+------------------+-------+------+
| 1 | 172.16.1.55:3306 | up | rw |
| 2 | 172.16.1.52:3306 | up | ro |
| 3 | 172.16.1.53:3306 | up | ro |
| 4 | 172.16.1.54:3306 | up | ro |
+-------------+------------------+-------+------+
user@127.0.0.1 [(none)] >add master 172.16.1.51:3306;
Empty set (0.00 sec)
user@127.0.0.1 [(none)] >add master 172.16.1.58:3306;
Empty set (0.00 sec)
user@127.0.0.1 [(none)] >select * from backends;
+-------------+------------------+-------+------+
| backend_ndx | address | state | type |
+-------------+------------------+-------+------+
| 1 | 172.16.1.55:3306 | up | rw |
| 2 | 172.16.1.51:3306 | up | rw |
| 3 | 172.16.1.58:3306 | down | rw |
| 4 | 172.16.1.54:3306 | up | ro |
| 5 | 172.16.1.52:3306 | up | ro |
| 6 | 172.16.1.53:3306 | up | ro |
+-------------+------------------+-------+------+
[root@db01 ~]# mysql -uuser -ppwd -h127.0.0.1 -P2345 -e "add slave 172.16.1.59:3306"
user@127.0.0.1 [(none)] >remove backend 6;MHA结合Atlas的脚本
#需知条件
1)宕机主库IP
down_master=$(sed -nr 's#^M.* (.*)\(.*\).*!$#\1#gp' ${mha_log})
2)新主库IP
new_master=`sed -nr 's#^M.* (.*)\(.*\) .*\.$#\1#gp' /etc/mha/logs/manager.log
1.安装atlas
2.写MHA结合Atlas的脚本
#!/bin/bash
#定义atlas管理用户
atlas_user=user
#定义atlas管理密码
atlas_password=pwd
#定义atlas管理主机 //MHA高可用vip
atlas_host=172.16.1.55
##定义atlas端口
atlas_port=2345
#定义atlas连接数据库
atlas_connect="mysql -u$atlas_user -p$atlas_password -h$atlas_host -P$atlas_port -e"
##定义MHA日志路径
mha_log=/etc/mha/logs/manager.log
#宕机IP
down_master=$(sed -nr 's#(.*)\(.*\) \(.*\)$#\1#gp' /etc/mha/logs/manager.log|head -1)
#新主库ip
new_master=$(sed -nr 's#(.*)\(.*\) \(.*\)$#\1#gp' /etc/mha/logs/manager.log|tail -1)
#新主库id
new_master_id=$(${atlas_connect} 'select * from backends'|/bin/grep "$new_master"|/bin/awk '{print $1}')
#配置文件移除新主库ip,添加旧主库IP
${atlas_connect} "remove backend ${new_master_id};add slave ${down_master}:3306;save config"
#循环重新下发atlas配置文件
for num in 51 52 53 54;do
ssh $new_master "scp /usr/local/mysql-proxy/conf/lol.cnf
172.16.1.$num:/usr/local/mysql-proxy/conf"
ssh 172.16.1.$num "systemctl restart atlas"
done
