





什么是索引?
1)索引就好比一本书的目录,它能让你更快的找到自己想要的内容。
2)让获取的数据更有目的性,从而提高数据库检索数据的性能。
给指定字段创建索引,索引会将该字段中所有数据进行排序
索引不是越多越好,创建索引,会占用磁盘空间
索引的排序方式
1)BTREE:B+树索引
2)HASH:HASH索引
3)FULLTEXT:全文索引
4)RTREE:R树索引
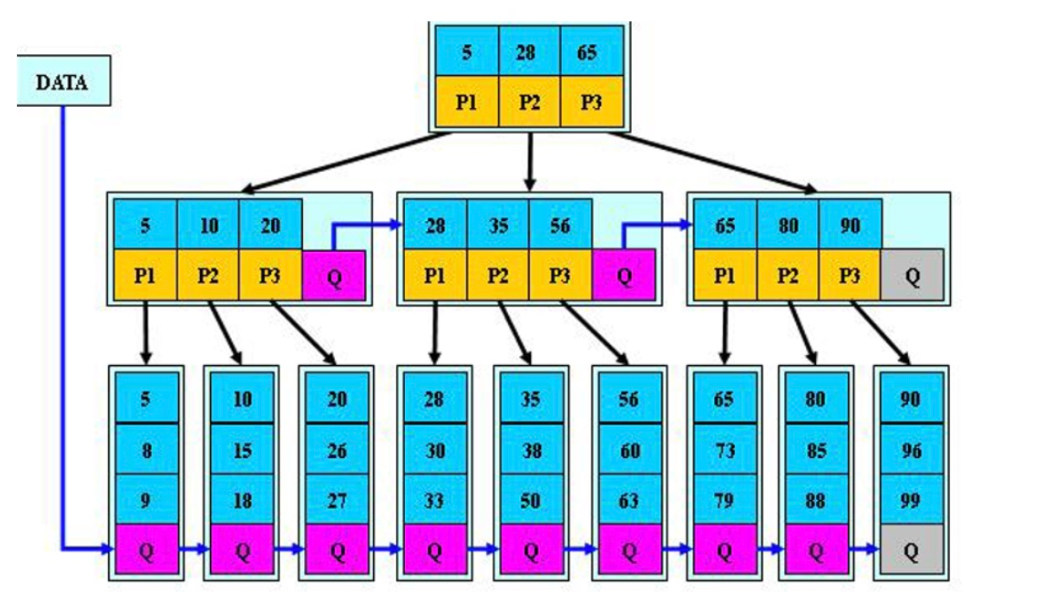
BTree
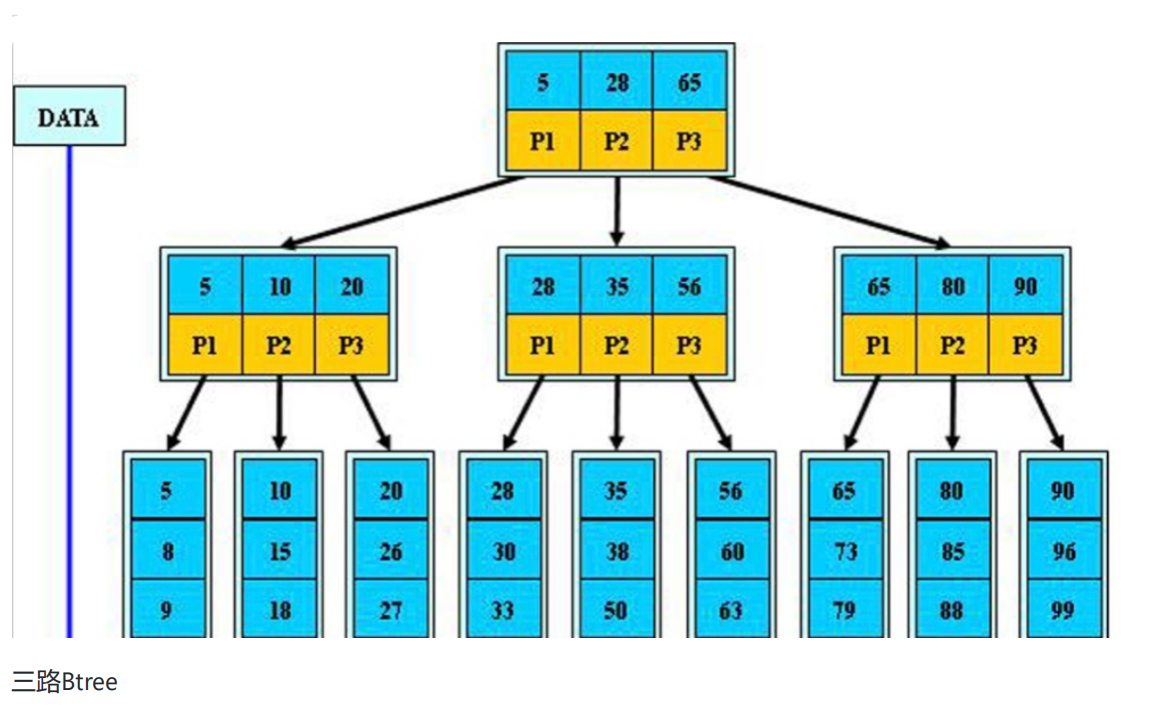
树索引可以分为:
根节点
枝节点
树叶节点
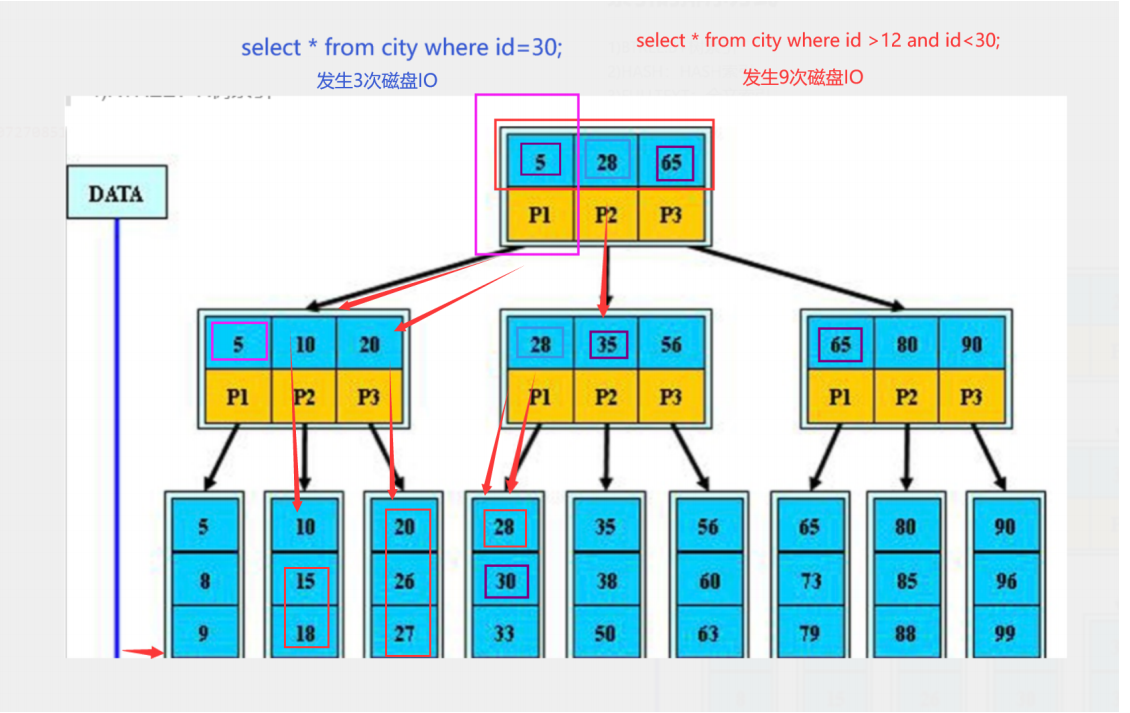
B+tree:
1)在叶子节点添加了相邻节点的指针
2)优化了范围查询,提升了范围查询的执行效率
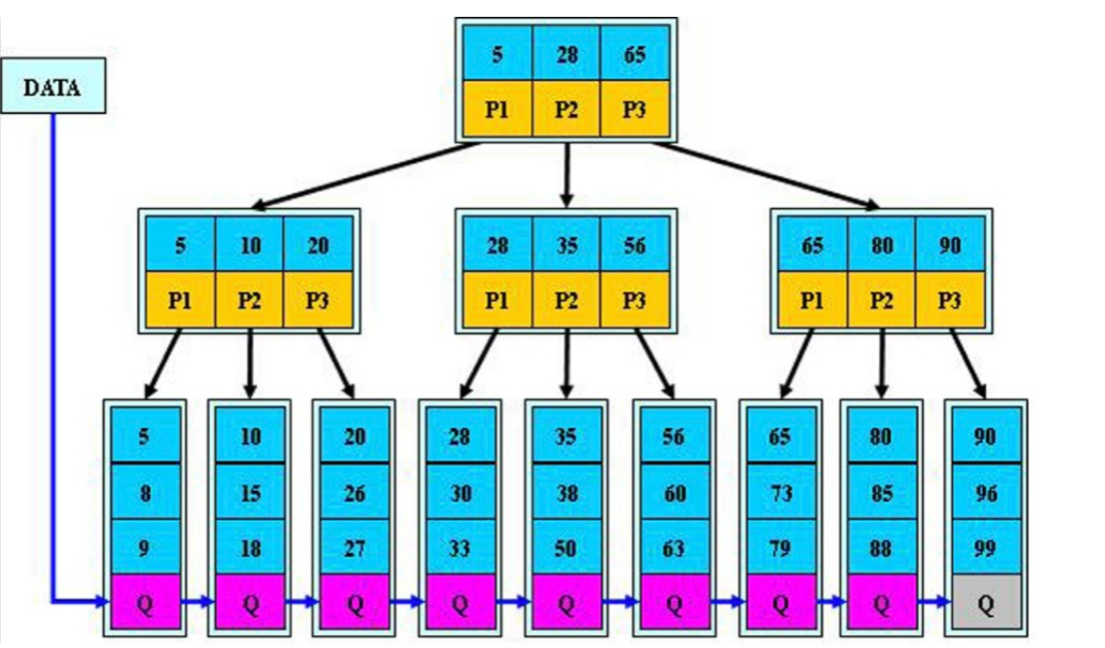
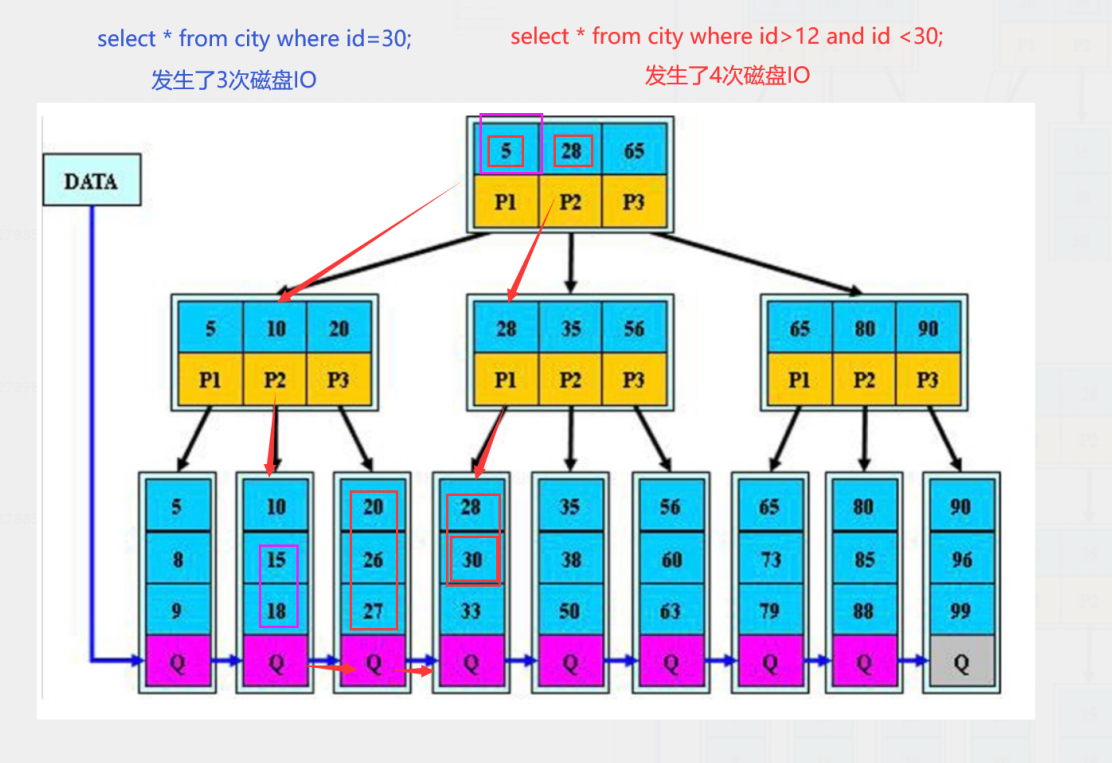

B*tree:
索引管理
索引分类:
- 主键索引(聚簇索引)
特性:唯一且非空- 联合索引
- 唯一键索引
特性:唯一 可以为空- 前缀索引
- 联合索引
- 普通索引
特性:可以不唯一,可以为空- 前缀索引
- 联合索引
索引的增删查
表数据准备:
#创表
root@localhost [test] >create table test.student(
id int,
name varchar(10),
age tinyint,
gender enum('m','f'),
phone char(11)
);
#写入数据
root@localhost [test] >insert into student values
(1,'zls',18,'m',11111111111),
(2,'a',12,'f',11111131111),
(3,'b',13,'f',11241131111),
(4,'a',14,'m',11121131111);
root@localhost [test] >select * from student;
+------+------+------+--------+-------------+
| id | name | age | gender | phone |
+------+------+------+--------+-------------+
| 1 | zls | 18 | m | 11111111111 |
| 2 | a | 12 | f | 11111131111 |
| 3 | b | 13 | f | 11241131111 |
| 4 | a | 14 | m | 11121131111 |
+------+------+------+--------+-------------+主键索引
#增
root@localhost [test] >alter table student add primary key(id);
Query OK, 4 rows affected (0.03 sec)
Records: 4 Duplicates: 0 Warnings: 0
#删
root@localhost [test] >alter table student drop primary key;
Query OK, 4 rows affected (0.05 sec)
Records: 4 Duplicates: 0 Warnings: 0
#查
root@localhost [test] >desc student;
+--------+---------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+---------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | 0 | |
| name | varchar(10) | YES | | NULL | |
| age | tinyint(4) | YES | | NULL | |
| gender | enum('m','f') | YES | | NULL | |
| phone | char(11) | YES | | NULL | |
+--------+---------------+------+-----+---------+-------+
5 rows in set (0.00 sec)
root@localhost [test] >show index from student;
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| student | 0 | PRIMARY | 1 | id | A | 4 | NULL | NULL | | BTREE | | |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+唯一键索引
#唯一键索引有个必须前提,需对列段数据进行统计去重,如果两个数值直接有差异则无法创建唯一键索引
#统计
root@localhost [test] >select count(age) from student;
+------------+
| count(age) |
+------------+
| 4 |
+------------+
1 row in set (0.00 sec)
#去重
root@localhost [test] >select count(distinct(age)) from student;
+----------------------+
| count(distinct(age)) |
+----------------------+
| 4 |
+----------------------+
1 row in set (0.00 sec)
#创建唯一键索引
#不定义索引名字://在创建唯一键索引的时候如果没有自定义名字。那么系统会默认以字段名位名;在删除的时候具有一定的风险
root@localhost [test] >alter table student add unique key(age);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
root@localhost [test] >show index from student;
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| student | 0 | PRIMARY | 1 | id | A | 4 | NULL | NULL | | BTREE | | |
| student | 0 | age | 1 | age | A | 4 | NULL | NULL | YES | BTREE | | |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
定义索引名字:
root@localhost [test] >alter table student add unique key un_age(age);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
root@localhost [test] >show index from student;
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| student | 0 | PRIMARY | 1 | id | A | 4 | NULL | NULL | | BTREE | | |
| student | 0 | un_age | 1 | age | A | 4 | NULL | NULL | YES | BTREE | | |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
#删除
没有定义名字的索引删除:
root@localhost [test] >alter table student drop index age;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
定义名字的索引删除:
root@localhost [test] >alter table student drop key un_age;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
注:删除的时候不管drop后面跟的是index或者key都可以删除普通索引
## 创建
#不起名情况下以字段名,命名 key和index都可以创建普通索引
root@localhost [test] >alter table student add key id_age(age);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
root@localhost [test] >alter table student add index id_age(age);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
## 删除
root@localhost [zls] >alter table student drop index id_age;
root@localhost [zls] >alter table student drop key id_age;前缀索引
什么是前缀索引?
创建索引时,按照指定数值对列进行排序
为什么使用前缀索引?
1)给大列创建索引时,可以减少排序时间,提升创建索引速度
2)insert,update,delete插入数据时,提升写入速度
3)提升查询速率
# 唯一键前缀索引创建
root@localhost [test] >alter table student add unique key id_age(age(1));
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
## 普通索引创建
root@localhost [test] >alter table student add key id_age(age(1));
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0联合索引
## 主键联合索引创建
root@localhost [test] >alter table student add primary key(id,name);
Query OK, 4 rows affected (0.05 sec)
Records: 4 Duplicates: 0 Warnings: 0
root@localhost [test] >show index from student;
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| student | 0 | PRIMARY | 1 | id | A | 4 | NULL | NULL | | BTREE | | |
| student | 0 | PRIMARY | 2 | name | A | 4 | NULL | NULL | | BTREE | | |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
2 rows in set (0.01 sec)
## 唯一键联合索引创建
root@localhost [test] >alter table student add unique key un_ai(id,age);
Query OK, 0 rows affected (0.13 sec)
Records: 0 Duplicates: 0 Warnings: 0
root@localhost [test] >show index from student;
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| student | 0 | un_ai | 1 | id | A | 4 | NULL | NULL | | BTREE | | |
| student | 0 | un_ai | 2 | age | A | 4 | NULL | NULL | YES | BTREE | | |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
2 rows in set (0.00 sec)
## 普通索引创建联合索引
root@localhost [test] >alter table student add key id_age(id,age);
Query OK, 0 rows affected (0.13 sec)
Records: 0 Duplicates: 0 Warnings: 0
root@localhost [test] >show index from student;
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| student | 0 | id_age | 1 | id | A | 4 | NULL | NULL | | BTREE | | |
| student | 0 | id_age | 2 | age | A | 4 | NULL | NULL | YES | BTREE | | |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
2 rows in set (0.00 sec
## 查询规则
alter table student add index idx_all(a,b,c,d);
where a.女生 and b.身高 and c.体重 and d.身材
index(a,b,c)
特点:前缀生效特性
a,ab,ac,abc,abcd 在搜索以a开头字段的时候可以走索引或部分走索引
b bc bcd cd c d ba ... 在搜索不以a开头字段的时候不走索引网站访问速度慢,如何排查,如何解决?
可以从以下几方面去分析:
网络问题
设备配置
代码bug
应用(nginx、lb、proxy)
数据库慢查询
使用explain分析SQL语句
慢查询,开启慢查询日志,记录执行速度慢的SQL语句
找出执行慢的SQL语句后,使用explain进行分析
#在my.cnf文件中mysqld添加如下即可:
slow_query_log = 1 # 启用慢查询日志,设置为1表示启用,设置为0表示禁用
slow_query_log_file = /path/to/slow_query.log # 慢查询日志文件的路径和文件名
long_query_time = 1 # 查询执行时间超过该阈值(单位:秒)将被记录到慢查询日志
#explain语法
root@localhost [test] >explain select * from student;
+----+-------------+---------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------+------+---------------+------+---------+------+------+-------+
| 1 | SIMPLE | student | ALL | NULL | NULL | NULL | NULL | 4 | NULL |
+----+-------------+---------+------+---------------+------+---------+------+------+-------+
1 row in set (0.00 sec)SQL语句执行区别
#从上到下,性能从最差到最好,我们认为至少要达到range级别
index:Full Index Scan,index与ALL区别为index类型只遍历索引树。(全索引扫描)
range:索引范围扫描,对索引的扫描开始于某一点,返回匹配值域的行。显而易见的索引范围扫描是带有between或者where子句里带有<,>查询。
ref:使用非唯一索引扫描或者唯一索引的前缀扫描,返回匹配某个单独值的记录行
eq_ref:类似ref,区别就在使用的索引是唯一索引,只有在连表查询时,使用join on才能出现
const、system:主键精确查询时
NULL:MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成
#在查询数据过多时可以使用limit分页查询方式优化结果集没有走索引的原因?
1)该字段没创建索引
2)创建索引了,但是没走
# 1.使用select * 查询数据不接where条件(杀个程序员祭天优化)
mysql> explain select * from city;
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| 1 | SIMPLE | city | ALL | NULL | NULL | NULL | NULL | 4188 | NULL |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
# 2.查询结果集大于25%
mysql> explain select * from city where population > 1000;
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | city | ALL | NULL | NULL | NULL | NULL | 4188 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
### 使用limit分页查询方式优化结果集
mysql> explain select * from city where population > 1000 limit 60;
+----+-------------+-------+-------+---------------+------+---------+------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+------+---------+------+------+-----------------------+
| 1 | SIMPLE | city | range | pop | pop | 4 | NULL | 4067 | Using index condition |
+----+-------------+-------+-------+---------------+------+---------+------+------+-----------------------+
# 3.使用字段列做计算(大嘴巴子抽前端优化)
mysql> explain select * from city where id-1=10;
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | city | ALL | NULL | NULL | NULL | NULL | 4188 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
# 4.隐式转换导致索引失效
创建表时,数据类型和查询时不一致导致,不走索引
字符串类型:加引号
mysql> explain select * from mysql.student where phone='21111111111';
+----+-------------+---------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | student | ALL | NULL | NULL | NULL | NULL | 4 | Using where |
+----+-------------+---------+------+---------------+------+---------+------+------+-------------+
数字类型:不加引号
mysql> explain select * from mysql.student where phone=11111111111;
+----+-------------+---------+------+---------------+------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------+------+---------------+------+---------+-------+------+-------+
| 1 | SIMPLE | student | ref | sjh | sjh | 9 | const | 1 | NULL |
+----+-------------+---------+------+---------------+------+---------+-------+------+-------+
# 5.使用like模糊查询时,%在前面的
mysql> explain select * from city where countrycode like '%H';
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | city | ALL | NULL | NULL | NULL | NULL | 4188 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
如果需求是必须百分号在前面,不要使用MySQL 请使用elastsearch
# 6.使用 <> 、 not in查询数据
mysql> explain select * from city where countrycode not in ('CHN','USA');
mysql> explain select * from city where countrycode <> 'CHN' and countrycode <> 'USA';
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | city | ALL | CountryCode | NULL | NULL | NULL | 4188 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
### 使用limit分页查询方式优化结果集
mysql> explain select * from city where countrycode <> 'CHN' and countrycode <> 'USA' limit 10;
+----+-------------+-------+-------+---------------+-------------+---------+------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+-------------+---------+------+------+-----------------------+
| 1 | SIMPLE | city | range | CountryCode | CountryCode | 3 | NULL | 3439 | Using index condition |
+----+-------------+-------+-------+---------------+-------------+---------+------+------+-----------------------+
# 7.联合索引,where条件后面没有按照创建索引的顺序查询
1.按顺序查
2.用户行为分析(数据分析)
# 8.索引损坏,失效
删了索引,重建,使用前缀索引索引创建原则
1)索引不是越多越好
索引的数目不是越多越好。每个索引都需要占用磁盘空间,索引越多,需要的磁盘空间就越大。
修改表时,对索引的重构和更新很麻烦。越多的索引,会使更新表变得很浪费时间。
2)有必要添加索引的列,如何选择索引?
删除不再使用或者很少使用的索引
表中的数据被大量更新,或者数据的使用方式被改变后,原有的一些索引可能不再需要。数据库管理
员应当定期找出这些索引,将它们删除,从而减少索引对更新操作的影响。
# 1.优先选择,唯一键索引
# 2.给经常要排序、分组这种查询的列,创建联合索引
# 3.普通索引尽量使用前缀索引
