





Redis-主从
一、Redis主从复制是什么?
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave);数据的复制是单向的,只能由主节点到从节点。
从 Redis 2.6 开始, 从服务器支持只读模式, 并且该模式为从服务器的默认模式。只读模式由 redis.conf 文件中的 slave-read-only 选项控制, 也可以通过 CONFIG SET parameter value (opens new window)命令来开启或关闭这个模式。只读从服务器会拒绝执行任何写命令, 所以不会出现因为操作失误而将数据不小心写入到了从服务器的情况。一个主服务器可以有多个从服务器,一个从服务器只能有一个主服务器,并且不支持主主复制。
不仅主服务器可以有从服务器,从服务器也可以有自己的从服务器, 多个从服务器之间可以构成一个主从链
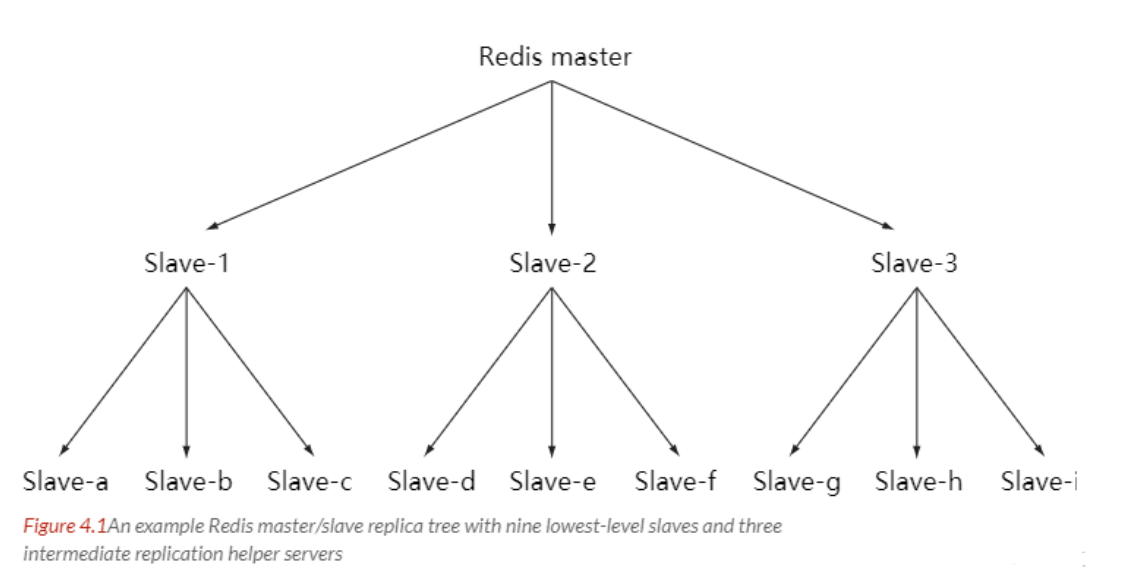
主从复制有哪些作用
数据备份:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复。
读写分离:由主节点提供写服务,由从节点提供读服务,提高Redis服务器的并发量。
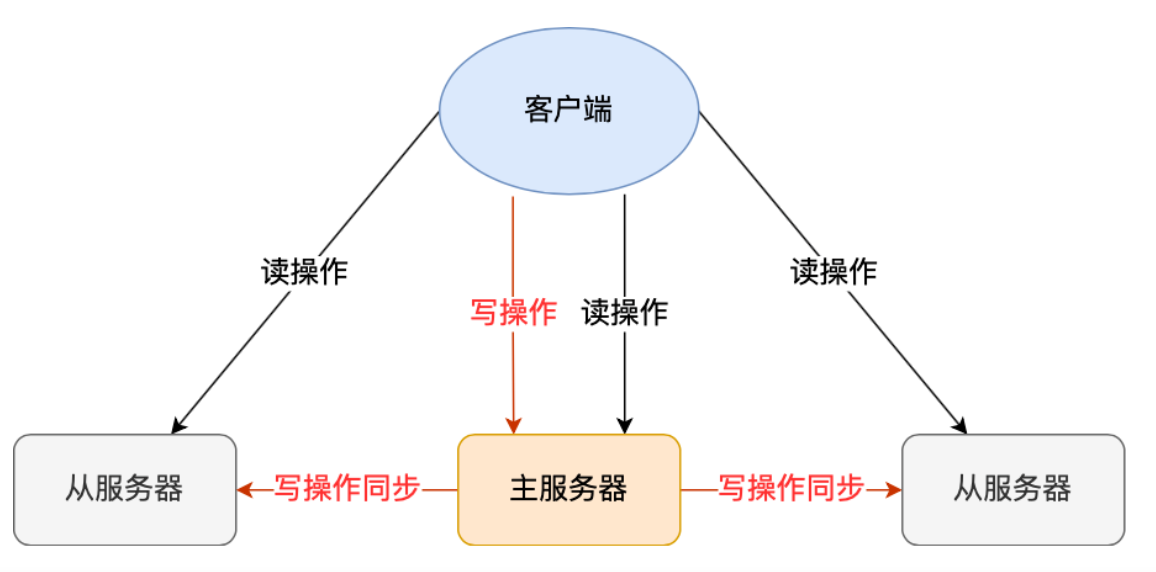
实现主从复制后可以将读操作分摊到从节点上:
- 读操作:主库、从库都可以接收;
- 写操作:首先到主库执行,然后,主库将写操作同步给从库。
二、主从复制功能
1)使用异步复制。
2)一个主服务器可以有多个从服务器。
3)从服务器也可以有自己的从服务器。
4)复制功能不会阻塞主服务器。
5)可以通过复制功能来让主服务器免于执行持久化操作,由从服务器去执行持久化操作即可
详解:
1)Redis 使用异步复制。从 Redis2.8开始,从服务器会以每秒一次的频率向主服务器报告复制流
(replication stream)的处理进度。
2)一个主服务器可以有多个从服务器。
3)不仅主服务器可以有从服务器,从服务器也可以有自己的从服务器,多个从服务器之间可以构成一
个图状结构。
4)复制功能不会阻塞主服务器:即使有一个或多个从服务器正在进行初次同步, 主服务器也可以继续
处理命令请求。
5)复制功能也不会阻塞从服务器:只要在 redis.conf 文件中进行了相应的设置, 即使从服务器正在进
行初次同步, 服务器也可以使用旧版本的数据集来处理命令查询。
6)在从服务器删除旧版本数据集并载入新版本数据集的那段时间内,连接请求会被阻塞。
7)还可以配置从服务器,让它在与主服务器之间的连接断开时,向客户端发送一个错误。
8)复制功能可以单纯地用于数据冗余(data redundancy),也可以通过让多个从服务器处理只读命
令请求来提升扩展性(scalability): 比如说,繁重的SORT命令可以交给附属节点去运行。
9)可以通过复制功能来让主服务器免于执行持久化操作:只要关闭主服务器的持久化功能,然后由从
服务器去执行持久化操作即可。
关闭主服务器上的持久化数据安全如何保证?
1.当配置Redis复制功能时,强烈建议打开主服务器的持久化功能。 否则的话,由于延迟等问题,部署的服务应该要避免自动拉起。
2.为了帮助理解主服务器关闭持久化时自动拉起的危险性,参考一下以下会导致主从服务器数据全部丢失的例子:
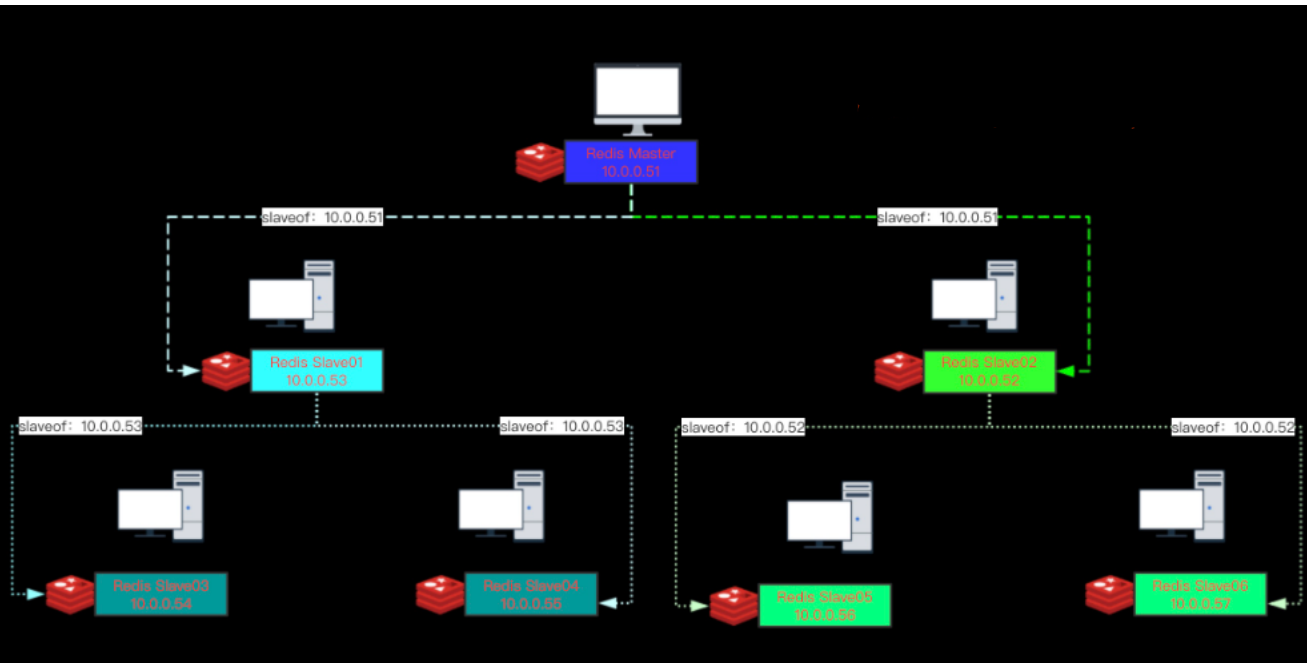
1)假设节点A为主服务器,并且关闭了持久化。并且节点B和节点C从节点A复制数据
2)节点A崩溃,然后由自动拉起服务重启了节点A. 由于节点A的持久化被关闭了,所以重启之后没有任何数据
3)节点B和节点C将从节点A复制数据,但是A的数据是空的,于是就把自身保存的数据副本删除。
结论:
1)在关闭主服务器上的持久化,并同时开启自动拉起进程的情况下,即便使用Sentinel来实现Redis的高可用性,也是非常危险的。因为主服务器可能拉起得非常快,以至于Sentinel在配置的心跳时间间隔内没有检测到主服务器已被重启,然后还是会执行上面的数据丢失的流程。
2)无论何时,数据安全都是极其重要的,所以应该禁止主服务器关闭持久化的同时自动拉起。
三、主从复制原理
redis 在复制时底层采用的是 psync 命令完成的数据主从同步,同步主要分为:全量复制和增量复制两种
全量复制:顾名思义也就是一次性把主节点数据全部发送给从节点,所以这种情况下,当数据量比较大时,会对主节点和网络造成很大的开销。
部分复制:用于处理主从复制时因网络中断等原因造成数据丢失的场景。当从节点再次和主节点连接时,主节点会补发丢失的数据。因为是补发,所以在发送的数据量一定是小于全量的数据。
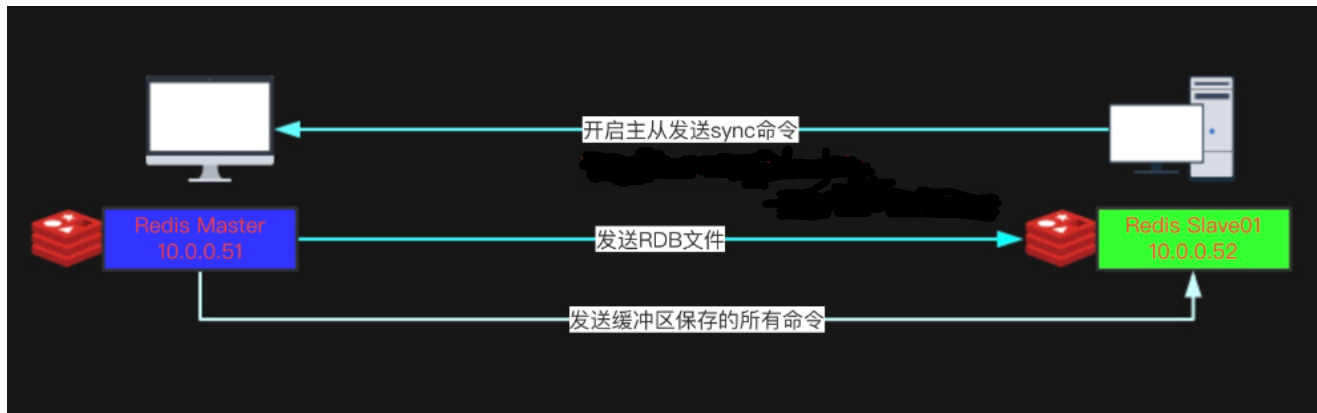
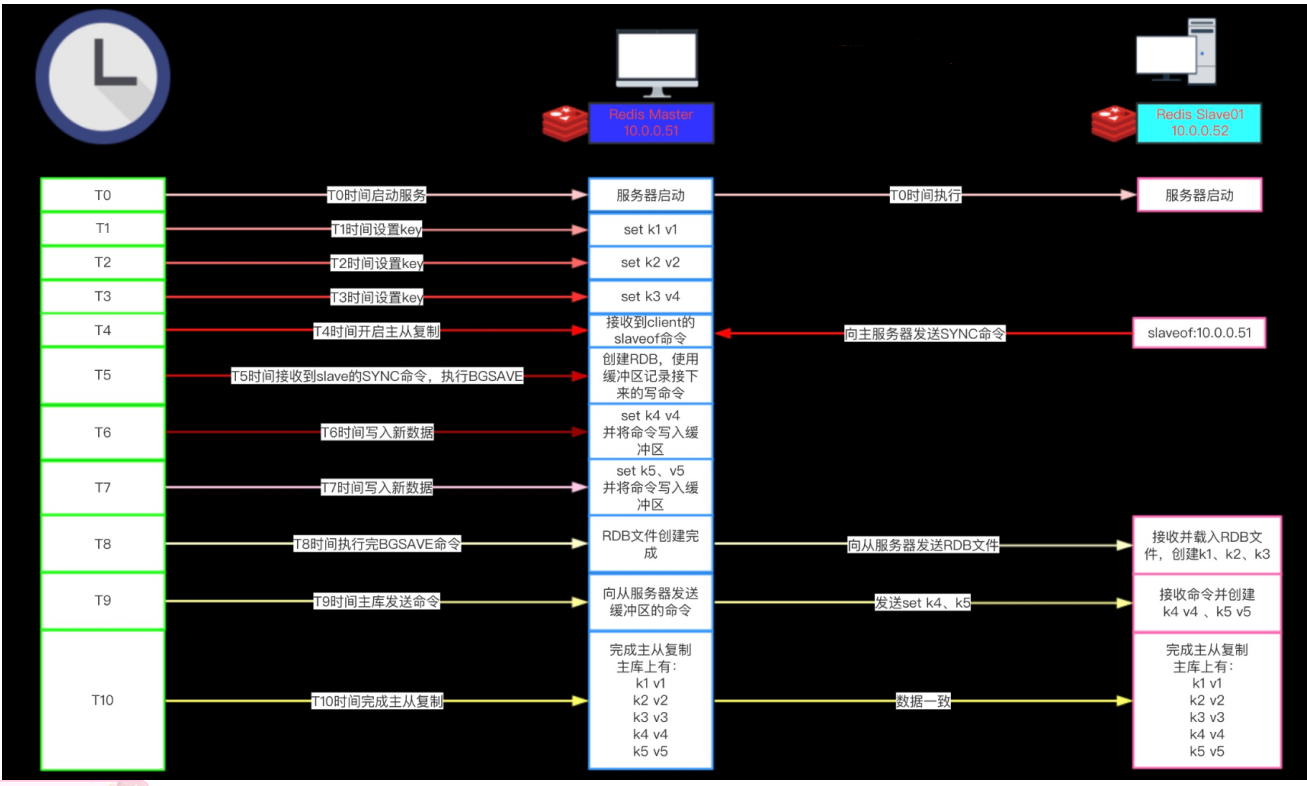
1)从服务器向主服务器发送 SYNC 命令。
2)接到 SYNC 命令的主服务器会调用BGSAVE 命令,创建一个 RDB 文件,并使用缓冲区记录接下来执行的所有写命令。
3)当主服务器执行完 BGSAVE 命令时,它会向从服务器发送 RDB 文件,而从服务器则会接收并载入这个文件。
4)主服务器将缓冲区储存的所有写命令发送给从服务器执行。
在主从服务器完成同步之后,主服务器每执行一个写命令,它都会将被执行的写命令发送给从服务器
执行,这个操作被称为“命令传播”(command propagate)。
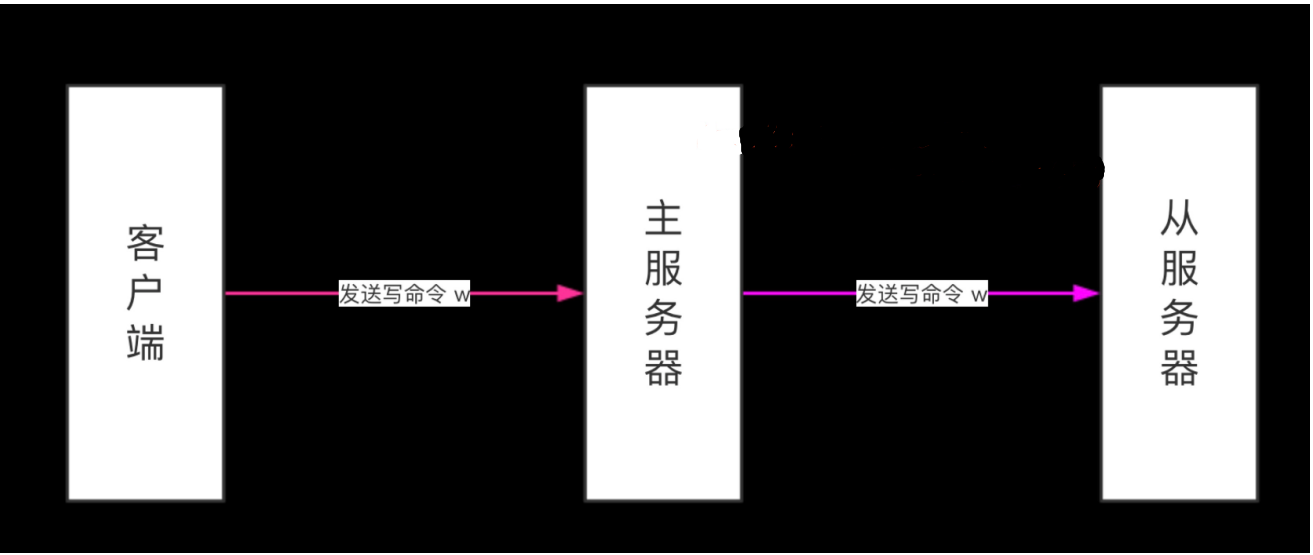
命令传播是一个持续的过程:只要复制仍在继续,命令传播就会一直进行,使得主从服务器的状态可
以一直保持一致。
四、Redis的断线重连
从库宕机后,重新连接主库时,如何保证数据集的完整性?
4.1、SYNC
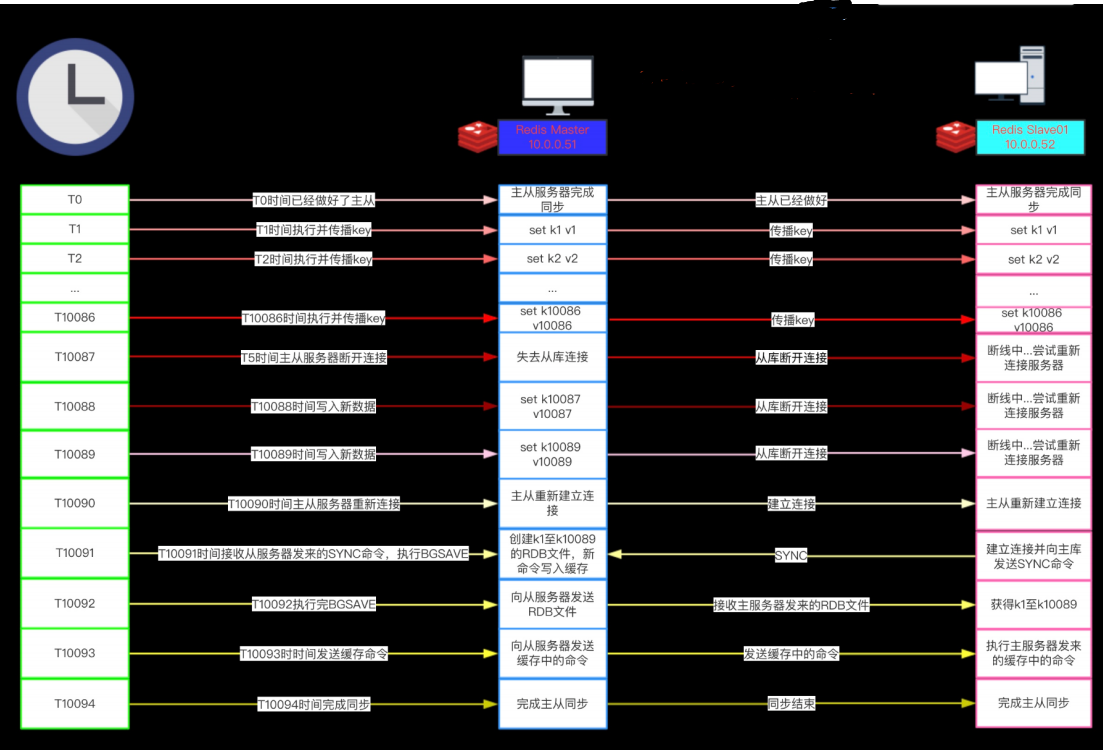
1)在 Redis2.8版本之前,断线之后重连的从服务器总要执行一次完整重同步(fullresynchronization)操作。
2)从 Redis2.8开始,Redis使用PSYNC命令代替SYNC命令。
3)PSYNC比起SYNC的最大改进在于PSYNC实现了部分重同步(partial resync)特性:在主从服务器断线并且重新连接的时候,只要条件允许,PSYNC可以让主服务器只向从服务器同步断线期间缺失的数据,而不用重新向从服务器同步整个数据库。
注:
PSYNC这个特性需要主服务器为被发送的复制流创建一个内存缓冲区(in-memory backlog), 并且主服务器和所有从服务器之间都记录一个复制偏移量(replication offset)和一个主服务器 ID(masterrun id),当出现网络连接断开时,从服务器会重新连接,并且向主服务器请求继续执行原来的复制进程:
- 1)如果从服务器记录的主服务器ID和当前要连接的主服务器的ID相同,并且从服务器记录的偏移量所指定的数据仍然保存在主服务器的复制流缓冲区里面,那么主服务器会向从服务器发送断线时缺失的那部分数据,然后复制工作可以继续执行。
- 2)否则的话,从服务器就要执行完整重同步操作。如果我们仔细地观察整个断线并重连的过程,就会发现:从服务器在断线之前已经拥有主服务器的绝大部分数据,要让主从服务器重新回到一致状态,从服务器真正需要的是 k10087、k10088和k10089这三个键的数据,而不是主服务器整个数据库的数据。
SYNC 命令在处理断线并重连时的做法——将主服务器的整个数据库重新同步给从服务器,是极度浪费的!
4.2、PSYNC
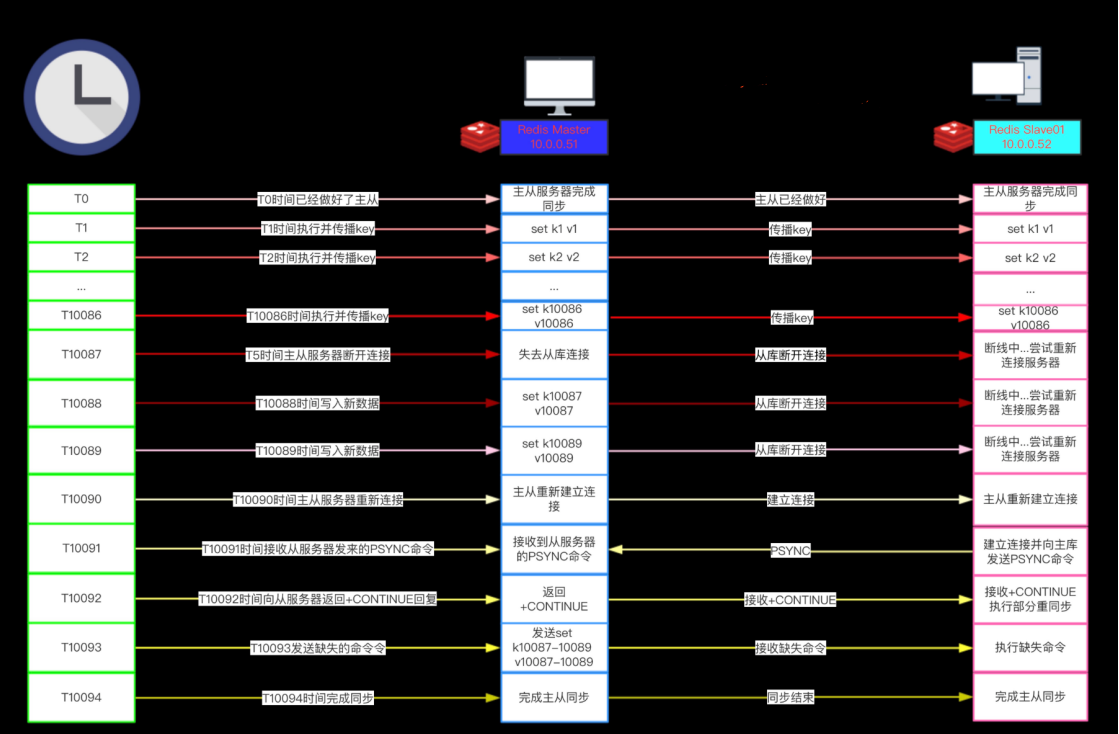
1)PSYNC只会将从服务器断线期间缺失的数据发送给从服务器。两个例子的情况是相同的,但SYNC需要发送包含整个数据库的 RDB 文件,而PSYNC 只需要发送三个命令。
2)如果主从服务器所处的网络环境并不那么好的话(经常断线),那么请尽量使用 Redis 2.8 或以上版本:通过使用 PSYNC 而不是 SYNC 来处理断线重连接,可以避免因为重复创建和传输 RDB文件而浪费大量的网络资源、计算资源和内存资源。
五、主从复制数据一致性问题
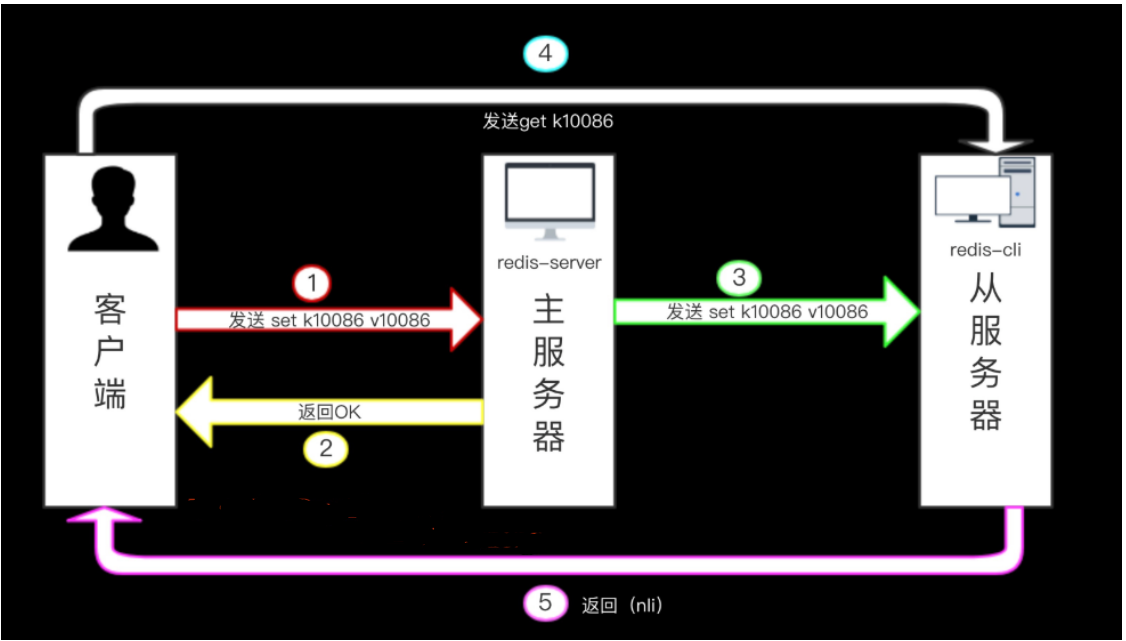
1)在读写分离环境下,客户端向主服务器发送写命令 SET k10086 v10086,主服务器在执行这个写命令之后,向客户端返回回复,并将这个写命令传播给从服务器。
2)接到回复的客户端继续向从服务器发送读命令 GET k10086 ,并且因为网络状态的原因,客户端的GET命令比主服务器传播的 SET 命令更快到达了从服务器。
3)因为从服务器键k10086的值还未被更新,所以客户端在从服务器读取到的将是一个错误(过期)的k10086值。
如何保证数据的安全性
1)主服务器只在有至少N个从服务器的情况下,才执行写操作
2)从Redis 2.8开始,为了保证数据的安全性,可以通过配置,让主服务器只在有至少N个当前已连接从服务器的情况下,才执行写命令。
3)不过,因为 Redis 使用异步复制,所以主服务器发送的写数据并不一定会被从服务器接收到,因此, 数据丢失的可能性仍然是存在的。
4)通过以下两个参数保证数据的安全:
#执行写操作所需的至少从服务器数量
min-slaves-to-write <number of slaves>
#指定网络延迟的最大值
min-slaves-max-lag <number of seconds>
#示例
min-slaves-to-write 1
min-slaves-max-lag 30这个特性的运作原理:
1)从服务器以每秒一次的频率 PING 主服务器一次, 并报告复制流的处理情况。主服务器会记录各个从服务器最后一次向它发送 PING 的时间。用户可以通过配置, 指定网络延迟的最大值 min-slaves-max-lag , 以及执行写操作所需的至少从服务器数量 min-slaves-to-write 。
2)如果至少有 min-slaves-to-write 个从服务器, 并且这些服务器的延迟值都少于 min-slaves-max-lag 秒, 那么主服务器就会执行客户端请求的写操作。你可以将这个特性看作 CAP 理论中的 C 的条件放宽版本: 尽管不能保证写操作的持久性, 但起码丢失数据的窗口会被严格限制在指定的秒数中。
3)另一方面, 如果条件达不到 min-slaves-to-write 和 min-slaves-max-lag 所指定的条件, 那么写操作就不会被执行, 主服务器会向请求执行写操作的客户端返回一个错误
六、多实例部署
#创建多实例目录
[root@db01 ~]# mkdir -p /etc/redis/{6379,6380}
#编辑多实例配置文件
[root@db01 ~]# cat /etc/redis/6379/redis.conf /etc/redis/6380/redis.conf
/etc/redis/6381/redis.conf
#redis 6379 配置文件
port 6379
daemonize yes
pidfile /etc/redis/6379/redis.pid
loglevel notice
logfile /etc/redis/6379/redis.log
dbfilename dump.rdb
dir /etc/redis/6379
bind 127.0.0.1 10.0.0.51
protected-mode no
#redis 6380 配置文件
port 6380
daemonize yes
pidfile /etc/redis/6380/redis.pid
loglevel notice
logfile /etc/redis/6380/redis.log
dbfilename dump.rdb
dir /etc/redis/6380
bind 127.0.0.1 10.0.0.51
protected-mode no
#启动redis多实例
[root@db01 ~]# redis-server /etc/redis/6379/redis.conf
[root@db01 ~]# redis-server /etc/redis/6380/redis.conf
#查看进程
[root@db01 ~]# ps -ef|grep redis
root 3570 1 0 22:44 ? 00:00:00 redis-server 127.0.0.1:6379
root 3574 1 0 22:44 ? 00:00:00 redis-server 127.0.0.1:6380七、主从切换(手动)
当主库宕机了,主从是如何切换的?
#停止主库 //6379为主库端口,6380为db01实例
[root@db01 ~]# systemctl stop redis
#从库取消身份
[root@db02 ~]# redis-cli -a 123 -p 6380
127.0.0.1:6380> slaveof no one
OK
#重新指向新主库
127.0.0.1:6380> slaveof 172.16.1.51 6380
OK
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:172.16.1.51
master_port:6380
master_link_status:up
master_last_io_seconds_ago:5
master_sync_in_progress:0
slave_read_repl_offset:7462
slave_repl_offset:7462
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:95c2a415d0200ced2e2029a7afe37adad7676f75
master_replid2:b452962e762b8c18ec4b893feee86434eba2b12a
master_repl_offset:7462
second_repl_offset:7463
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2969
repl_backlog_histlen:4494Redis-高可用Sentinel
一、什么是Sentinel(哨兵)
Redis-Sentinel是Redis官方推荐的高可用性(HA)解决方案,当用Redis做Master-slave的高可用方案时,假如master宕机了,Redis本身(包括它的很多客户端)都没有实现自动进行主备切换,而Redis-sentinel本身也是一个独立运行的进程,它能监控多个master-slave集群,发现master宕机后能进行自动切换。
Sentinel结构:
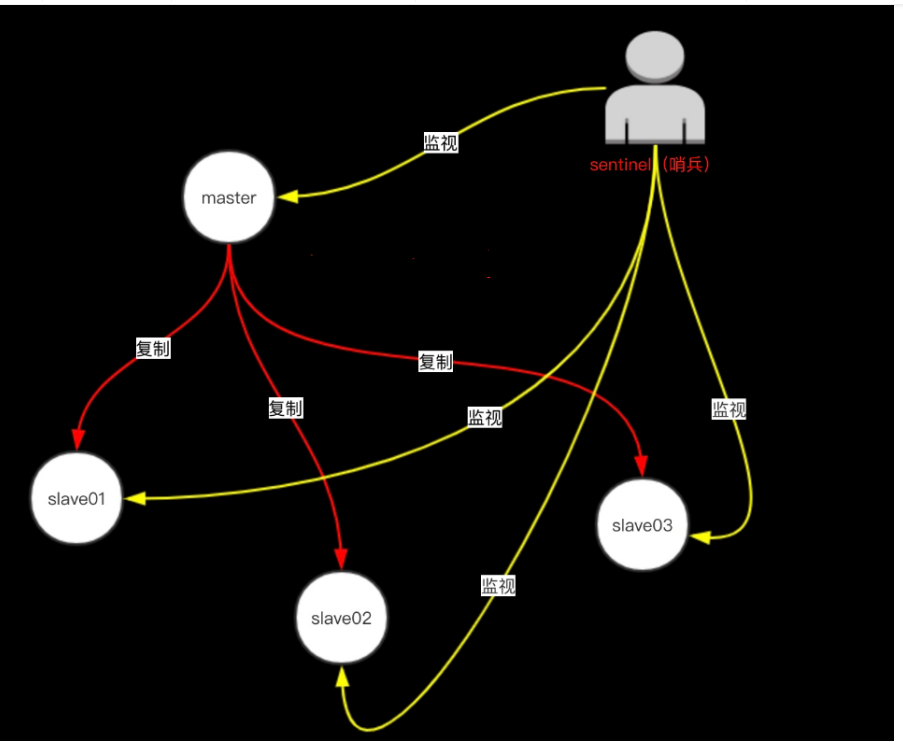
在 redis3.0 以前的版本要实现集群一般是借助哨兵 sentinel 工具来监控 master 节点的状态,如果 master 节点异常,则会做主从切换,将某一台 slave 作为 master,哨兵的配置略微复杂,并且性能和高可用性等各方面表现一般,特别是在主从切换的瞬间存在访问瞬断的情况,而且哨兵模式只有一个主节点对外提供服务,没法支持很高的并发,且单个主节点内存也不宜设置得过大,否则会导致持久化文件过大,影响数据恢复或主从同步的效率
二、Sentinel主要工作流程
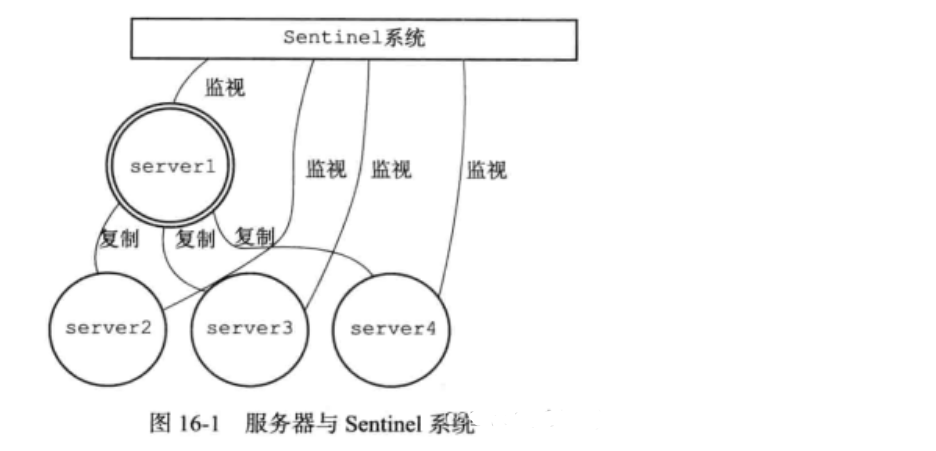
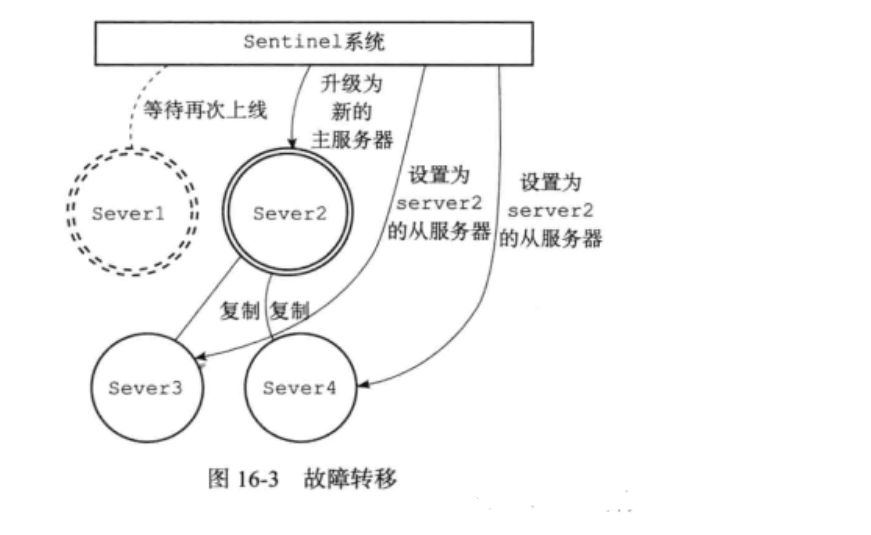
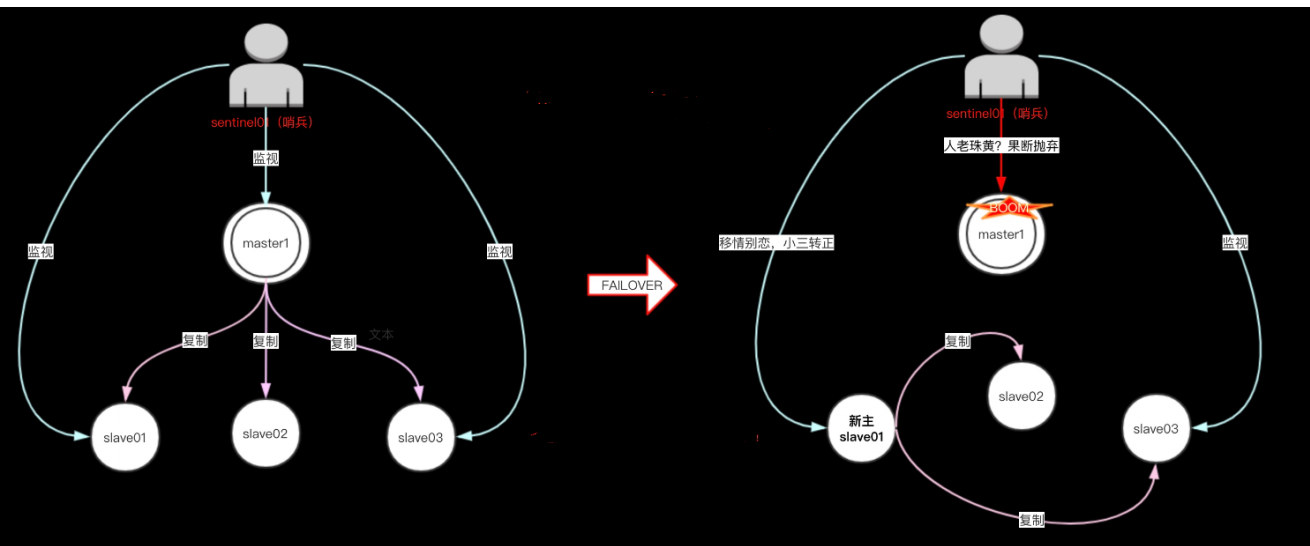
当监察到主服务器下线:
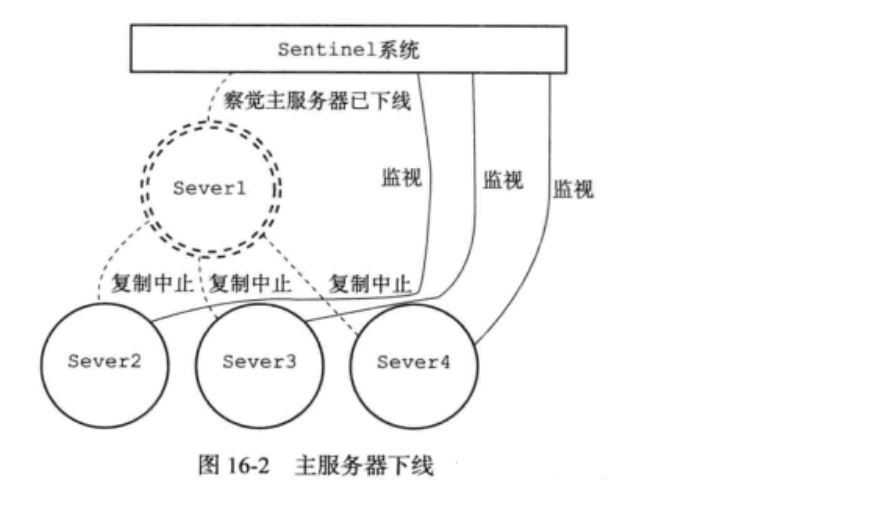
sentinel系统就会自动在从服务器中挑选一个升级为新的主服务器,代替已下线的旧主服务器,并让其他从服务器成为新主服务器的从服务器。
当旧的主服务器上线后,降级为新的主服务器的从服务器:
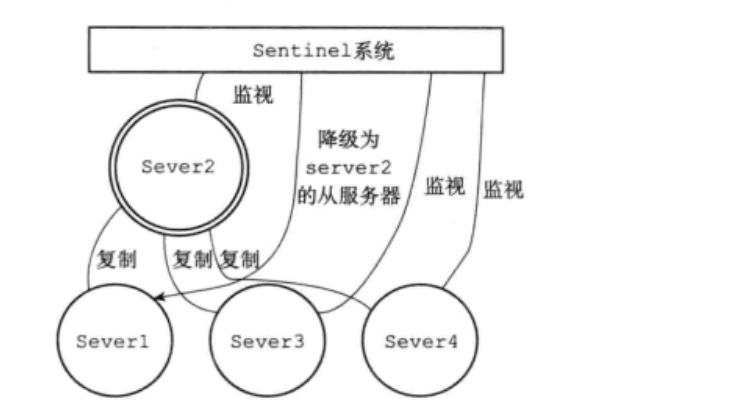
这样,就实现了故障转移,实现高可用
三、Sentinel功能
1)监控(Monitoring):Sentinel会不断地检查你的主服务器和从服务器是否运作正常。
2)提醒(Notification):当被监控的某个Redis服务器出现问题时,Sentinel可以通过API向管理员或者其他应用程序发送通知。
3)自动故障迁移(Automatic failover):当一个主服务器不能正常工作时,Sentinel会开始一次自动故障迁移操作,它会将失效主服务器的其中一个从服务器升级为新的主服务器,并让失效主服务器的其他从服务器改为复制新的主服务器;当客
户端试图连接失效的主服务器时,集群也会向客户端返回新主服务器的地址,使得集群可以使用新主服务器代替失效服务器
3.1、Sentinel如何发现主库从库?
Sentinel通过用户给定的配置文件来发现主服务器。
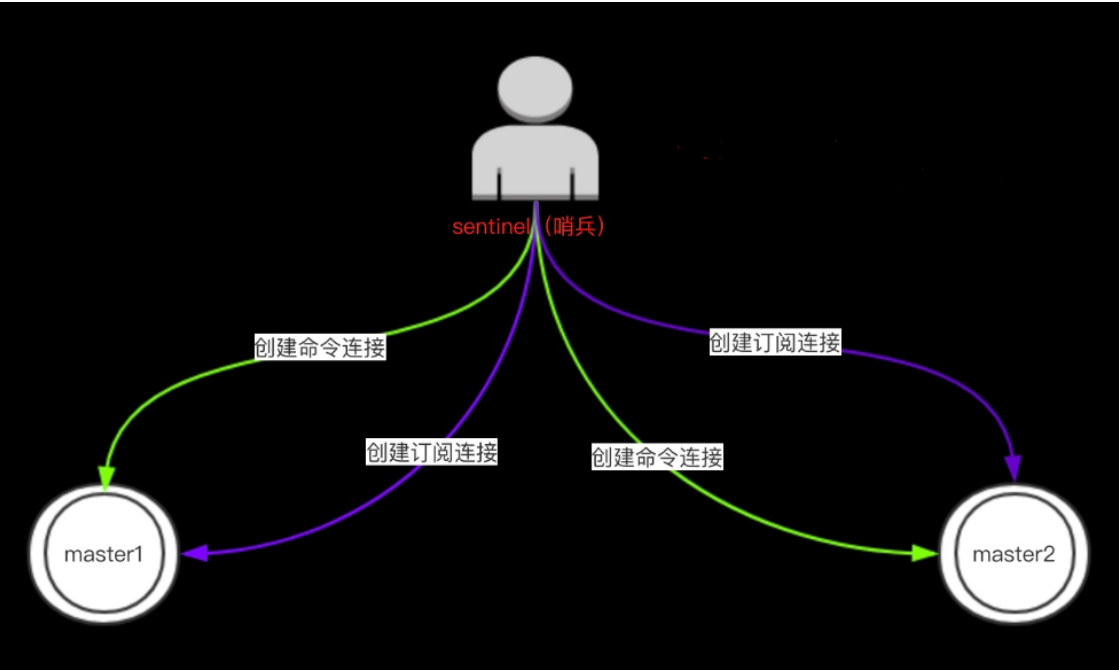
创建两个链接:
- 订阅连接(一个哨兵,可以通过订阅连接,发现其他哨兵)
- 命令连接(通过主库执行info replication发现其他从库)
2)切换时,取消从库身份,其他从库指向新主库
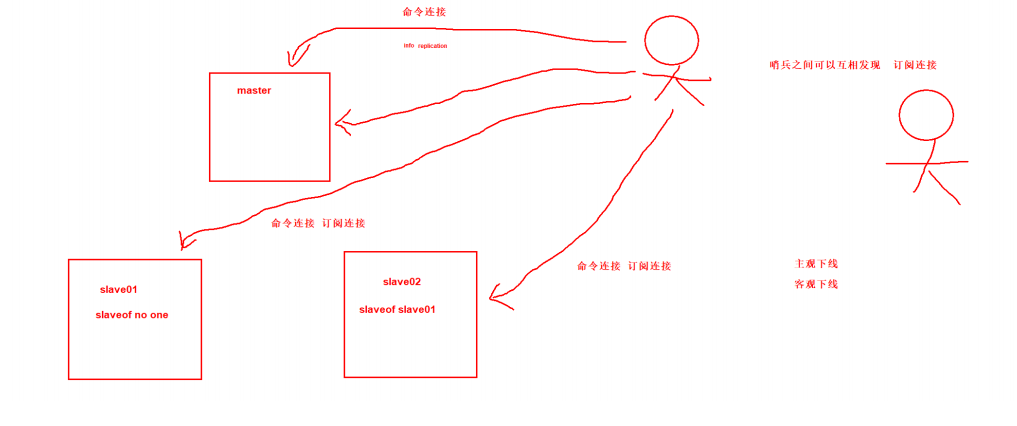
3.2、如何发现从库?
Sentinel通过向主服务器发送INFO命令来自动获得所有从服务器的地址。
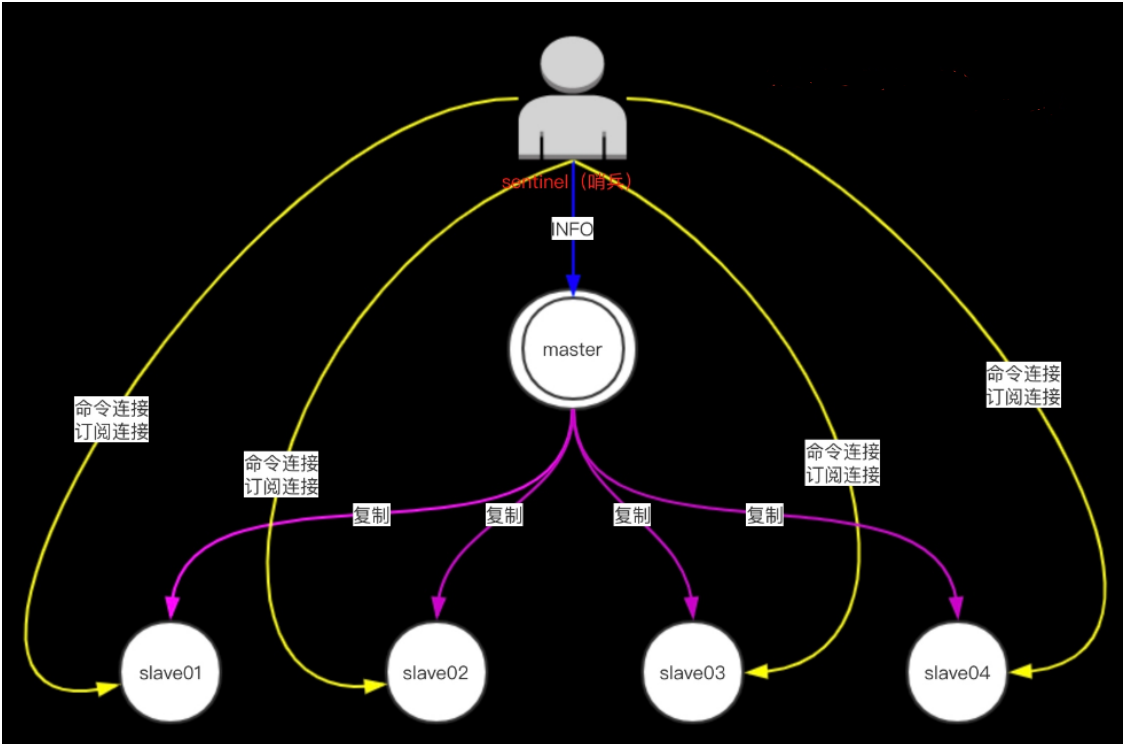
跟主服务器一样,Sentinel 会与每个被发现的从服务器创建命令连接和订阅连接。
3.3、如何发现其他哨兵?
Sentinel 会通过命令连接向被监视的主从服务器发送 “HELLO” 信息,该消息包含 Sentinel 的 IP、端号、ID 等内容,以此来向其他 Sentinel 宣告自己的存在。与此同时Sentinel 会通过订阅连接接收其他
Sentinel 的“HELLO” 信息,以此来发现监视同一个主服务器的其他 Sentinel 。
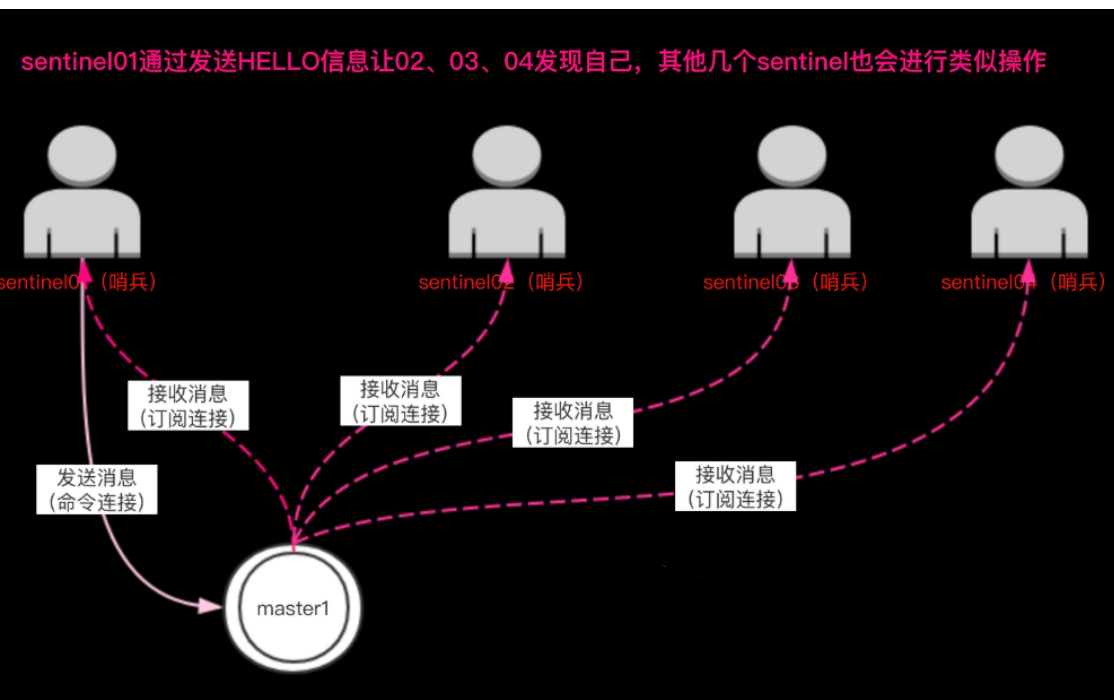
1)一个Sentinel可以与其他多个Sentinel进行连接,各个Sentinel之间可以互相检查对方的可用性,并进行信息交换。你无须为运行的每个 Sentinel 分别设置其他 Sentinel 的地址,因为Sentinel可以通过发布与订阅功能来自动发现正在监视相同主服务器的其他 Sentinel ,这一功能是通过向频道sentinel:hello发送信息来实现的。
2)与此类似,你也不必手动列出主服务器属下的所有从服务器,因为 Sentinel 可以通过询问主服务器来获得所有从服务器的信息。每个Sentinel会以每两秒一次的频率,通过发布与订阅功能,向被它监视的所有主服务器和从服务器的sentinel:hello频道发送一条信息,信息中包含了Sentinel的IP地址、端口号和运行ID(runid)。
3)每个Sentinel都订阅了被它监视的所有主服务器和从服务器的sentinel:hello 频道,查找之前未出现过的sentinel(looking for unknown sentinels)。当一个Sentinel发现一个新的Sentinel时,它会将新的Sentinel添加到一个列表中,这个列表保存了Sentinel已知的,监视同一个主服务器的所有其他Sentinel 。Sentinel发送的信息中还包括完整的主服务器当前配置(configuration)。如果一个Sentinel 包含的主服务器配置比另一个Sentinel发送的配置要旧,那么这个 Sentinel 会立即升级到新配置上。
4)在将一个新 Sentinel 添加到监视主服务器的列表上面之前,Sentinel 会先检查列表中是否已经包含了和要添加的 Sentinel 拥有相同运行 ID 或者相同地址(包括 IP 地址和端口号)的 Sentinel ,如果是的话,Sentinel 会先移除列表中已有的那些拥有相同运行 ID或者相同地址的 Sentinel ,然后再添加新Sentinel 。
3.4、多个哨兵之间连接
Sentinel之间只会互相创建命令连接,用于进行通信。因为已经有主从服务器作为发送和接收HELLO信息的中介,所以Sentinel之间不会创建订阅连接。
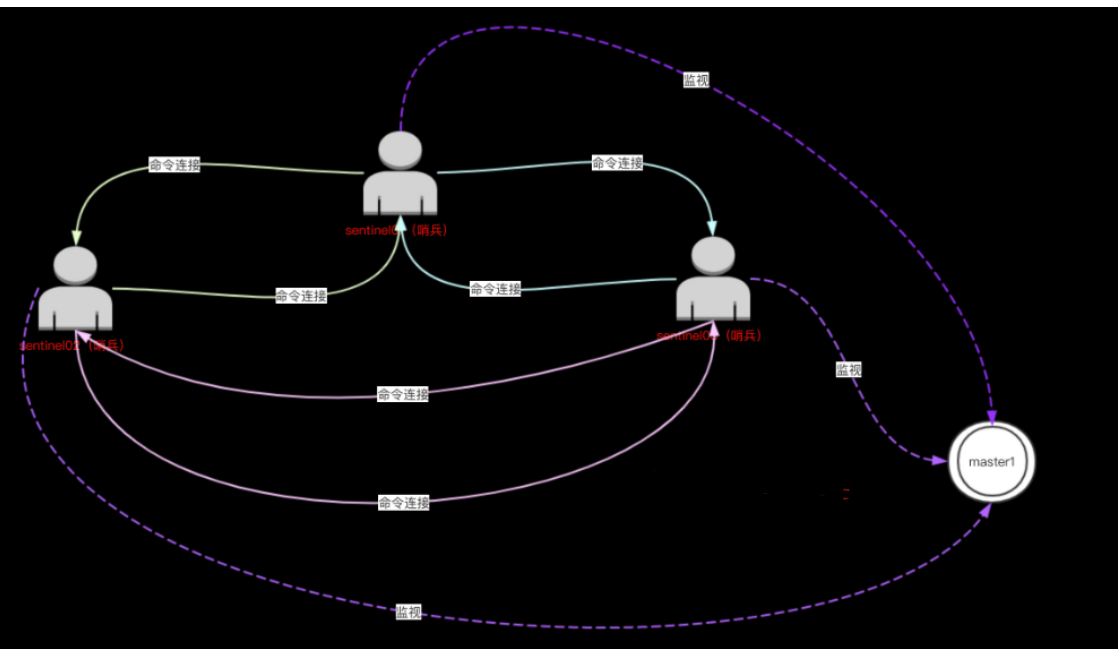
3.5、哨兵如何做切换
Sentinel使用PING命令来检测实例的状态:如果实例在指定的时间内没有返回回复,或者返回错误的回复,那么该实例会被 Sentinel 判断为下线。
Redis的Sentinel中关于下线(down)有两个不同的概念:
1)主观下线(Subjectively Down, 简称 SDOWN)指的是单个 Sentinel 实例对服务器做出的下线断。
2)客观下线(Objectively Down,简称 ODOWN)指的是多个Sentinel实例在对同一个服务器做出SDOWN判断,并且通过SENTINEL is-master-down-by-addr命令互相交流之后,得出的服务器下线判断。(一个 Sentinel可以通过向另一个Sentinel发送SENTINEL is-master-down-by-addr命令来询问对方是否认为给定的服务器已下线。)
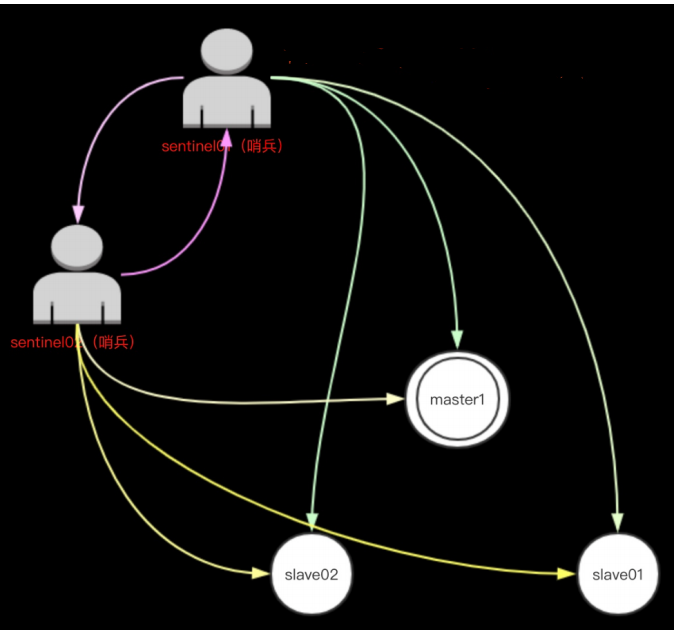
如果一个服务器没有在 master-down-after-milliseconds 选项所指定的时间内,对向它送PING命令的Sentinel返回一个有效回复(valid reply),那么Sentinel就会将这个服务器标记为主观下线。服务器对PING命令的有效回复可以是以下三种回复的其中一种:
1)返回 +PONG 。
2)返回 -LOADING 错误。
3)返回 -MASTERDOWN 错误。
如果服务器返回除以上三种回复之外的其他回复,又或者在指定时间内没有回复Ping命令,那么Sentinel认为服务器返回的回复无效(non-valid)。
注意:一个服务器必须在master-down-after-milliseconds毫秒内,一直返回无效回复才会被Sentinel标记为主观下线。
举个例子,如果master-down-after-milliseconds选项的值为30000毫秒(30秒),那么只要服务器能在每29秒之内返回至少一次有效回复,这个服务器就仍然会被认为是处于正常状态的。
从主观下线状态切换到客观下线状态并没有使用严格的法定人数算法(strong quorum algorithm),而是使用了流言协议:如果 Sentinel 在给定的时间范围内,从其他Sentinel那里接收到了足够数量的主
服务器下线报告,那么Sentinel就会将主服务器的状态从主观下线改变为客观下线。如果之后其他Sentinel不再报告主服务器已下线,那么客观下线状态就会被移除。
客观下线条件只适用于主服务器:对于任何其他类型的Redis实例,Sentinel在将它们判断为下线前不需要进行协商,所以从服务器或者其他 Sentinel 永远不会达到客观下线条件。
只要一个Sentinel发现某个主服务器进入了客观下线状态,这个Sentinel就可能会被其他Sentinel推选出,并对失效的主服务器执行自动故障迁移操作。
3.6、故障转移步骤
一次故障转移操作由以下步骤组成:
1)发现主服务器已经进入客观下线状态。
2)基于Raft leader election协议 ,进行投票选举
3)如果当选失败,那么在设定的故障迁移超时时间的两倍之后,重新尝试当选。如果当选成功,那么执行以下步骤。
4)选出一个从服务器,并将它升级为主服务器。
5)向被选中的从服务器发送 SLAVEOF NO ONE 命令,让它转变为主服务器。
6)通过发布与订阅功能,将更新后的配置传播给所有其他Sentinel,其他Sentinel对它们自己的配置进行更新。
7)向已下线主服务器的从服务器发送SLAVEOF命令,让它们去复制新的主服务器。
8)当所有从服务器都已经开始复制新的主服务器时, leader Sentinel 终止这次故障迁移操作。
3.7、选举规则
Sentinel使用以下规则来选择新的主服务器:
1)在失效主服务器属下的从服务器当中,那些被标记为主观下线、已断线、或者最后一次回复PING命令的时间大于五秒钟的从服务器都会被淘汰。
2)在失效主服务器属下的从服务器当中,那些与失效主服务器连接断开的时长超过down-after选项指定的时长十倍的从服务器都会被淘汰。
3)在经历了以上两轮淘汰之后剩下来的从服务器中,我们选出复制偏移量(replication offset)最大的那个从服务器作为新的主服务器;
4)如果复制偏移量不可用,或者从服务器的复制偏移量相同,那么带有最小运行ID的那个从服务器成为新的主服务器
3.8、Sentinel故障切换后如何保持数据一致的
Sentinel自动故障迁移的一致性特质:
1)Sentinel自动故障迁移使用Raft算法来选举领头(leader)Sentinel ,从而确保在一个给定的周期(epoch)里,只有一个领头产生。
2)这表示在同一个周期中, 不会有两个 Sentinel 同时被选中为领头,并且各个 Sentinel 在同一个节点中只会对一个领头进行投票。
3)更高的配置节点总是优于较低的节点,因此每个 Sentinel 都会主动使用更新的节点来代替自己的配置。简单来说,我们可以将Sentinel配置看作是一个带有版本号的状态。一个状态会以最后写入者胜出(last-write-wins)的方式(也即是,最新的配置总是胜出)传播至所有其他Sentinel。
3.9、sentinel持久化配置
Sentinel状态的持久化:
1)Sentinel 的状态会被持久化在 Sentinel 配置文件里面。
2)每当Sentinel接收到一个新的配置,或者当领头Sentinel为主服务器创建一个新的配置时,这个配置会与配置节点一起被保存到磁盘里面。
3)这意味着停止和重启Sentinel进程都是安全的。
四、Sentinel实战
环境准备:
| 主机 | IP | 角色 | 应用 |
|---|---|---|---|
| db01 | 172.16.1.51 | 主库 | redis-server、redis-client、redis-sentinel |
| db02 | 172.16.1.52 | 从库 | redis-server、redis-client |
| db03 | 172.16.1.53 | 从库 | redis-server、redis-client |
4.1、主从复制部署
参考前面文章即可
4.2、 部署sentinel
## 编辑sentinel配置
[root@db01 ~]# vim /app/redis/sentinel.conf
port 26379
daemonize yes
dir "/app/redis/data"
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 5000
sentinel auth-pass mymaster 123
## 启动sentinel
[root@db01 ~]# redis-sentinel /app/redis/sentinel.conf
#端口检查 //26379
[root@db01 ~]# netstat -lntup
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 172.16.1.51:6379 0.0.0.0:* LISTEN 18976/redis-server
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 18976/redis-server
tcp 0 0 0.0.0.0:26379 0.0.0.0:* LISTEN 18536/redis-sentine
tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN 6010/rpcbind
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 6901/sshd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 6998/master
tcp6 0 0 :::26379 :::* LISTEN 18536/redis-sentine
tcp6 0 0 :::111 :::* LISTEN 6010/rpcbind
tcp6 0 0 :::22 :::* LISTEN 6901/sshd
tcp6 0 0 ::1:25 :::* LISTEN 6998/master
udp 0 0 0.0.0.0:611 0.0.0.0:* 6010/rpcbind
udp 0 0 0.0.0.0:111 0.0.0.0:* 6010/rpcbind
udp6 0 0 :::611 :::* 6010/rpcbind
udp6 0 0 :::111 :::* 6010/rpcbindsentinel monitor mymaster 127.0.0.1 6379 2 :
Sentinel 去监视一个名为mymaster的主服务器,这个主服务器的IP地址为127.0.0.1,端口号为6379,而将这个主服务器判断为失效至少需要2个Sentinel同意(只要同意Sentinel的数量不达标,自动故障迁移就不会执行,不过要注意,无论你设置要多少个Sentinel同意才能判断一个服务器失效,一个Sentinel 都需要获得系统中多数(majority) Sentinel 的支持,才能发起一次自动故障迁移,并预留一个给定的配置节点(configuration Epoch,一个配置节点就是一个新主服务器配置的版本号)。换句话说,在只有少数(minority)Sentinel进程正常运作的情况下,Sentinel 是不能执行自动故障迁移
的。
sentinel down-after-milliseconds mymaster 5000 :指定了Sentinel认为服务器已经断线所需的毫秒数。如果服务器在给定的毫秒数之内,没有返回Sentinel发送的Ping命令的回复,或者返回一个错误,那么Sentinel将这个服务器标记为主观下线(subjectively down,简称SDOWN)。不过只有一个Sentinel将服务器标记为主观下线并不一定会引起服务器的自动故障迁移:只有在足够数量的Sentinel都将一个服务器标记为主观下线之后,服务器才会被标记为客观下线(objectively down, 简称 ODOWN ),这时自动故障迁移才会执行。
sentinel failover-timeout mymaster 180000 :
自动故障切换的超时时间
sentinel parallel-syncs mymaster 1 :
在执行故障转移时,最多可以有多少个从服务器同时对新的主服务器进行同步,这个数字越小,完成故障转移所需的时间就越长。如果从服务器被设置为允许使用过期数据集(参见对 redis.conf 文件中对 slave-serve-stale-data 选项的说明),那么你可能不希望所有从服务器都在同一时间向新的主服务器发送同步请求,因为尽管复制过程的绝大部分步骤都不会阻塞从服务器,但从服务器在载入主服务器发来的 RDB 文件时,仍然会造成从服务器在一段时间内不能处理命令请求:如果全部从服务器一起对新的主服务器进行同步,那么就可能会造成所有从服务器在短时间内全部不可用的情况出现。可通过将这个值设为1来保证每次只有一个从服务器处于不能处理命令请求的状态。

