一、什么是集群结构?
集群就是使用网络将若干台计算机联通起来,并提供统一的管理方式,使其对外呈现单机的服务效果
二、集群的作用
1、主从复制不能实现高可用
2、随着公司发展,用户数量增多,并发越来越多,业务需要更高的QPS,而主从复制中单机的QPS可能无法满足业务需求
3、数据量的考虑,现有服务器内存不能满足业务数据的需要时,单纯向服务器添加内存不能达到要求,此时需要考虑分布式需求,把数据分布到不同服务器上
4、网络流量需求:业务的流量已经超过服务器的网卡的上限值,可以考虑使用分布式来进行分流
5、离线计算,需要中间环节缓冲等别的需求
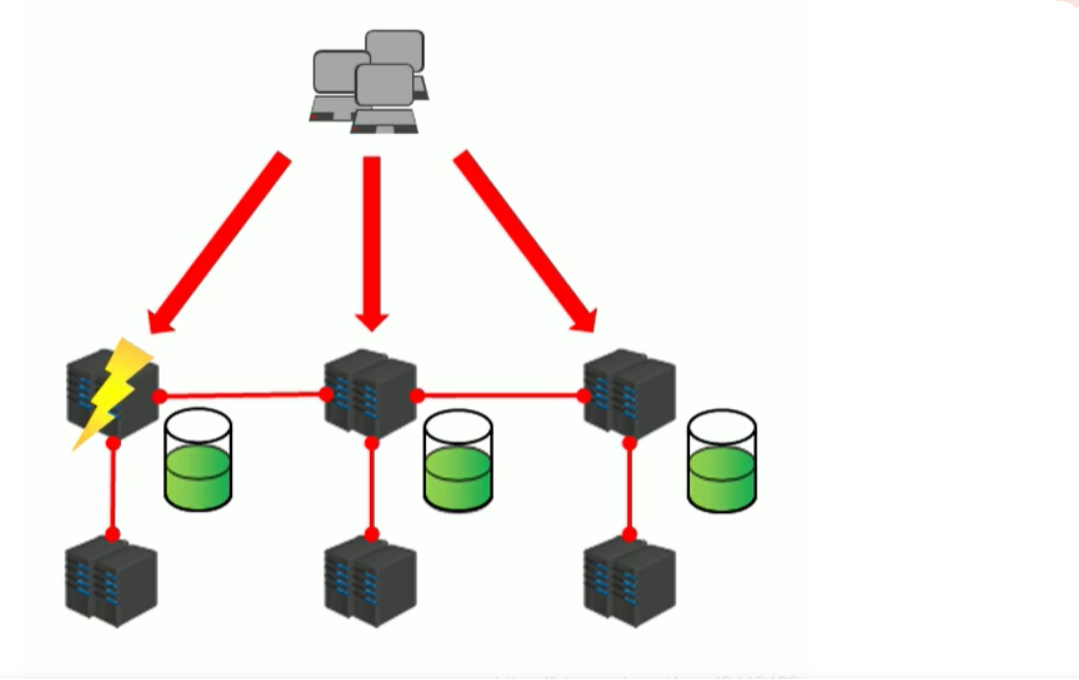
三、集群内部的设计
3.1、数据存储结构
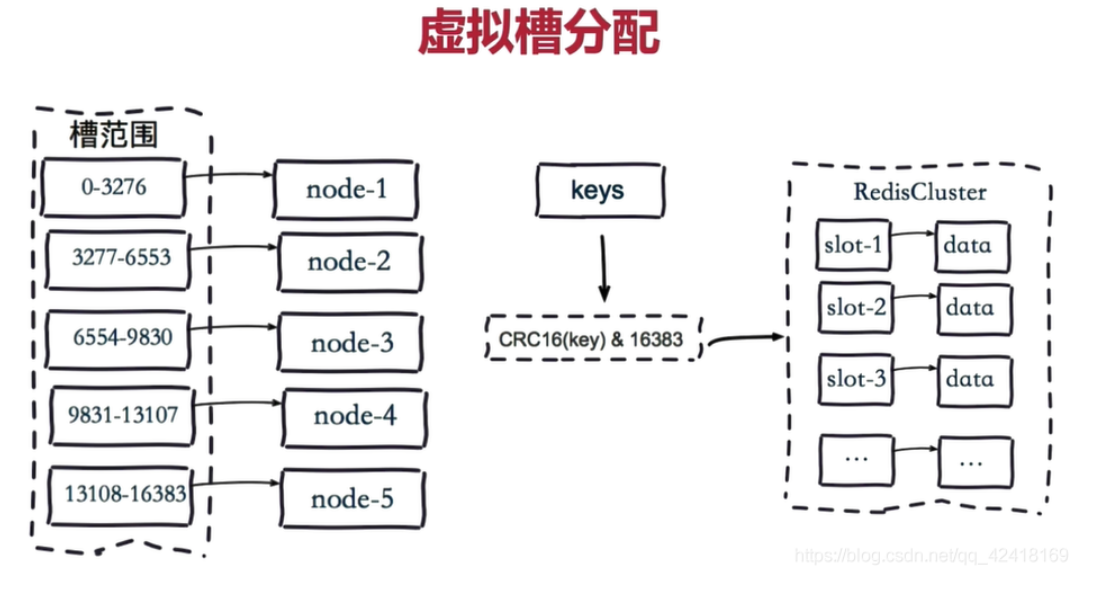
虚拟槽分区是Redis Cluster采用的分区方式
预设虚拟槽,每个槽就相当于一个数字,有一定范围。每个槽映射一个数据子集,一般比节点数大
虚拟槽分布方式中,由于每个节点管理一部分数据槽,数据保存到数据槽中。当节点扩容或者缩容时,对数据槽进行重新分配迁移即可,数据不会丢失
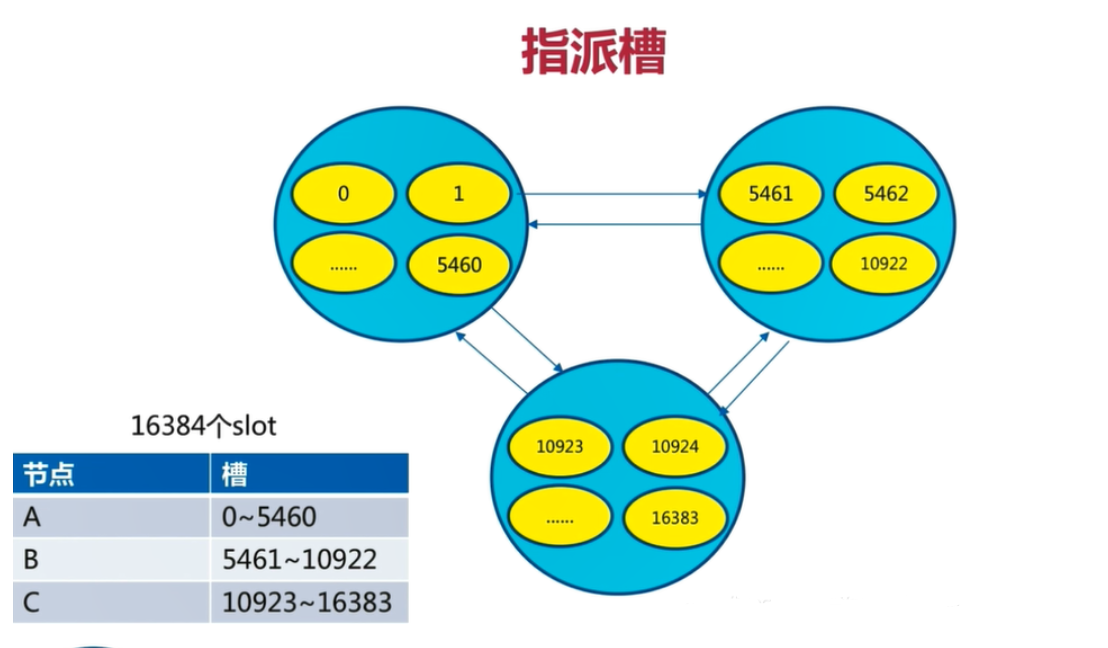
3.1.1、Redis Cluster中预设虚拟槽的范围为0到16383
3.1.1、数据存储的步骤
把16384槽按照节点数量进行平均分配,由节点进行管理
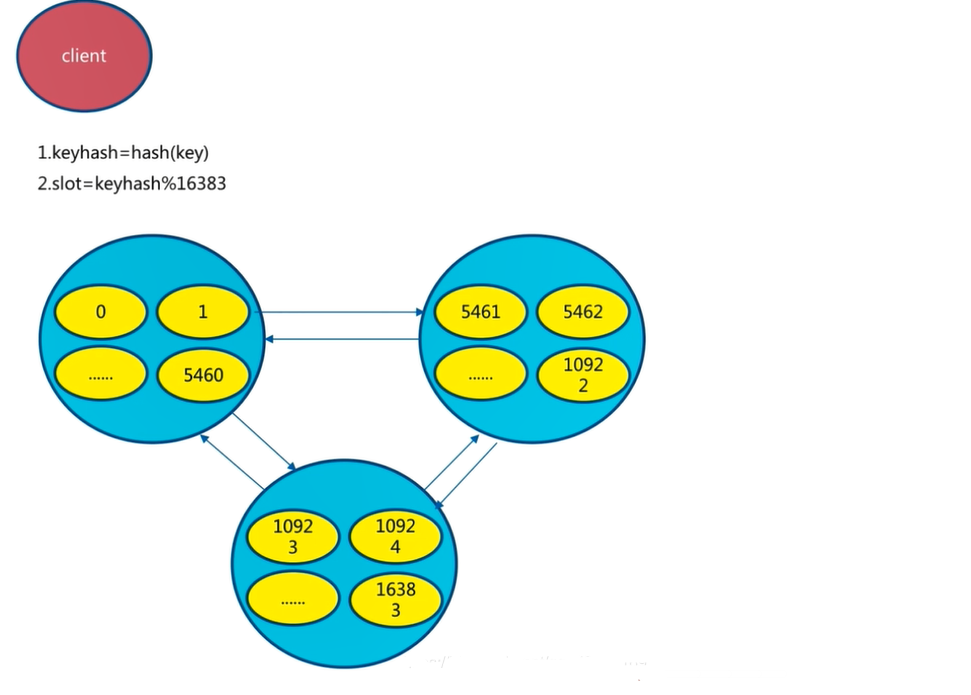
对每个key按照CRC16规则进行hash运算
把hash结果对16383进行取余
把余数发送给Redis节点
节点接收到数据,验证是否在自己管理的槽编号的范围如果在自己管理的槽编号范围内,则把数据保存到数据槽中,然后返回执行结果
如果在自己管理的槽编号范围外,则会把数据发送给正确的节点,由正确的节点来把数据保存在对应的槽中
3.1.2、节点消息共享
需要注意的是:Redis Cluster的节点之间会共享消息,每个节点都会知道是哪个节点负责哪个范围内的数据槽
3.2、Redis Cluster基本架构
3.2.1、1.节点
Redis Cluster是分布式架构:即Redis Cluster中有多个节点,每个节点都负责进行数据读写操作每个节点之间会进行通信。
3.2.2、2.meet
节点之间会相互通信 meet操作是节点之间完成相互通信的基础,meet操作有一定的频率和规则
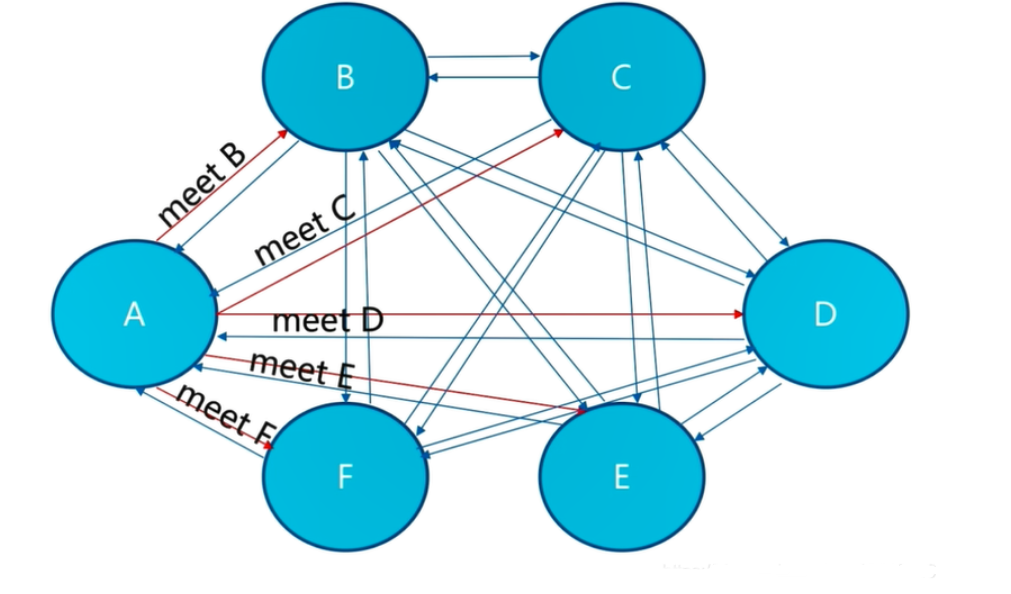
3.2.3、3.分配虚拟槽
把16384个槽平均分配给节点进行管理,每个节点只能对自己负责的槽进行读写操作由于每个节点之间都彼此通信,每个节点都知道另外节点负责管理的槽范围
客户端访问任意节点时,对数据key按照CRC16规则进行hash运算,然后对运算结果对16383进行取作,如果余数在当前访问的节点管理的槽范围内,则直接返回对应的数据如果不在当前节点负责管理的槽范围内,则会告诉客户端去哪个节点获取数据,由客户端去正确的节点获取数据
3.2.4、4.复制
保证高可用,每个主节点都有一个从节点,当主节点故障,Cluster会按照规则实现主备的高可用性
对于节点来说,有一个配置项:cluster-enabled,即是否以集群模式启动
3.2.5、5.客户端路由
每个节点通过通信都会共享Redis Cluster中槽和集群中对应节点的关系
客户端向Redis Cluster的任意节点发送命令,接收命令的节点会根据CRC16规则进行hash运算与16383取余,计算自己的槽和对应节点
如果保存数据的槽被分配给当前节点,则去槽中执行命令,并把命令执行结果返回给客户端
如果保存数据的槽不在当前节点的管理范围内,则向客户端返回moved重定向异常
客户端接收到节点返回的结果,如果是moved异常,则从moved异常中获取目标节点的信息
客户端向目标节点发送命令,获取命令执行结果
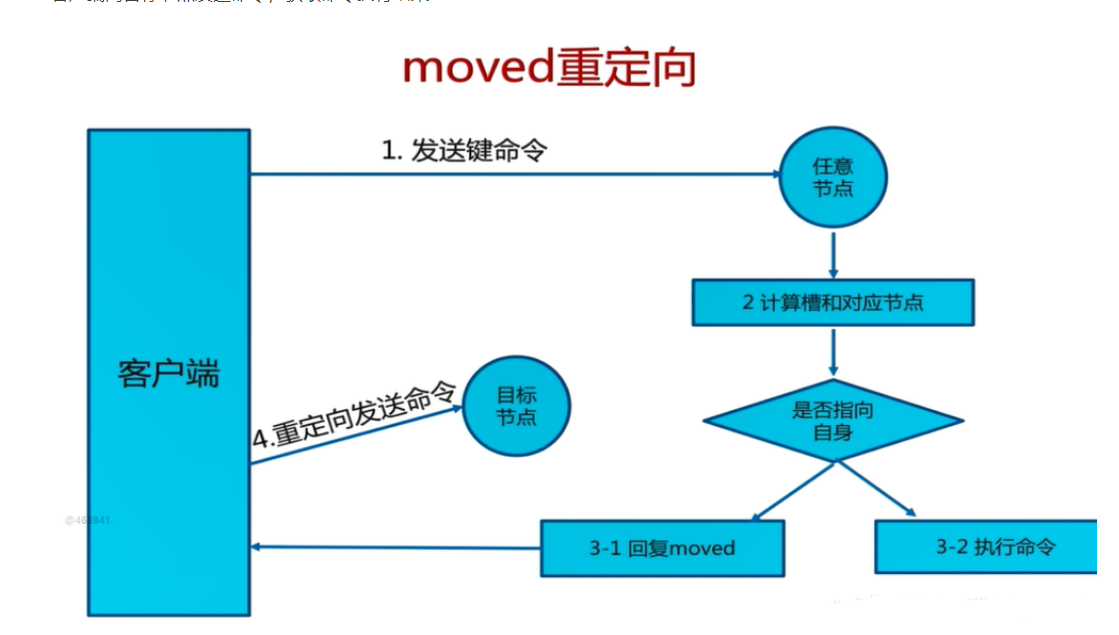
需要注意的是:客户端不会自动找到目标节点执行命令
四、主从下线
4.1、从(slave)服务器下线时
当任意一个从属服务器下线时,所对应的主(master)会记录它的id,以便在下次上线时给对应的从属服务器恢复状态,数据4.2、主(master)服务器下线时
当任意一个主服务器下线时,集群会进行投票,确认服务器的下线状态,如果确定主服务器宕机下线,会从这个服务器所在的从属结构里面的从属服务器里面投票选出一个服务器来当主服务器,等原master上线时,cluster就会将它的状态改为slave五、cluster常用的配置和命令
5.1、cluster配置
- 设置加入cluster,成为其中的节点
cluster-enabled yes|no- cluster配置文件名,该文件属于自动生成,仅用于快速查找文件并查询文件内容
cluster-config-file <filename>- 节点服务响应超时时间,用于判定该节点是否下线或切换为从节点
cluster-node-timeout <milliseconds>- master连接的slave最小数量
cluster-migration-barrier <count>5.2、cluster命令
有关cluster常用命令可以在redis-cli里面通过help @cluster来获取
- 查看所有的节点信息
cluster nodes- 添加一个新节点
cluster meet [ip:port]- 提供有关Redis集群节点状态的信息
cluster info- 从节点表中删除节点
cluster forget [node-id]六、集群搭建
6.1、集群搭建的环境
Redis集群至少需要3个节点,因为投票容错机制要求超过半数节点认为某个节点挂了该节点才是挂了,所以2个节点无法构成集群
要保证集群的高可用,需要每个节点都有从节点,也就是备份节点,所以Redis集群至少需要6台服务器。因为我没有那么多服务器,也启动不了那么多虚拟机,所在这里搭建的是伪分布式集群,即一台服务器虚拟运行6个redis实例,修改端口号为(6380-6385),当然实际生产环境的Redis集群搭建和这里是一样的。
安装ruby
环境准备:
| 主机名 | 外网IP | 端口 | 角色 |
|---|---|---|---|
| db01 | 10.0.0.51 | 6380 | master |
| db01 | 10.0.0.51 | 6381 | slave |
| db01 | 10.0.0.51 | 6382 | master |
| db01 | 10.0.0.51 | 6383 | slave |
| db01 | 10.0.0.51 | 6384 | master |
| db01 | 10.0.0.51 | 6385 | slave |
#多实例创建主从,自行参考文档6.2、第一步(修改配置文件,启动服务器)
我们采用简单的配置
主库配置文件中的内容如下(这里以redis.conf为例):
#主库6380
port 6380
daemonize yes
pidfile /app/redis/6380/redis.pid
loglevel notice
logfile /app/redis/6380/redis.log
dbfilename dump.rdb
dir /app/redis/6380
bind 127.0.0.1 172.16.1.51
protected-mode no
requirepass 123
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
#主库6382
port 6382
daemonize yes
pidfile /app/redis/6382/redis.pid
loglevel notice
logfile /app/redis/6382/redis.log
dbfilename dump.rdb
dir /app/redis/6382
bind 127.0.0.1 172.16.1.51
protected-mode no
requirepass 123
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
#主库6384
port 6384
daemonize yes
pidfile /app/redis/6384/redis.pid
loglevel notice
logfile /app/redis/6384/redis.log
dbfilename dump.rdb
dir /app/redis/6384
bind 127.0.0.1 172.16.1.51
protected-mode no
requirepass 123
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes 从库配置:
#从库6381
port 6381
daemonize yes
pidfile /app/redis/6381/redis.pid
loglevel notice
logfile /app/redis/6381/redis.log
dbfilename dump.rdb
dir /app/redis/6381
bind 127.0.0.1 172.16.1.51
protected-mode no
requirepass 123
masterauth 123
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
#从库6383
port 6383
daemonize yes
pidfile /app/redis/6383/redis.pid
loglevel notice
logfile /app/redis/6383/redis.log
dbfilename dump.rdb
dir /app/redis/6383
bind 127.0.0.1 172.16.1.51
protected-mode no
requirepass 123
masterauth 123
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
#从库6385
port 6385
daemonize yes
pidfile /app/redis/6385/redis.pid
loglevel notice
logfile /app/redis/6385/redis.log
dbfilename dump.rdb
dir /app/redis/6385
bind 127.0.0.1 172.16.1.51
protected-mode no
requirepass 123
masterauth 123
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes 启动6个服务器
使用netstat -lntup | grep '[6]38*'查看
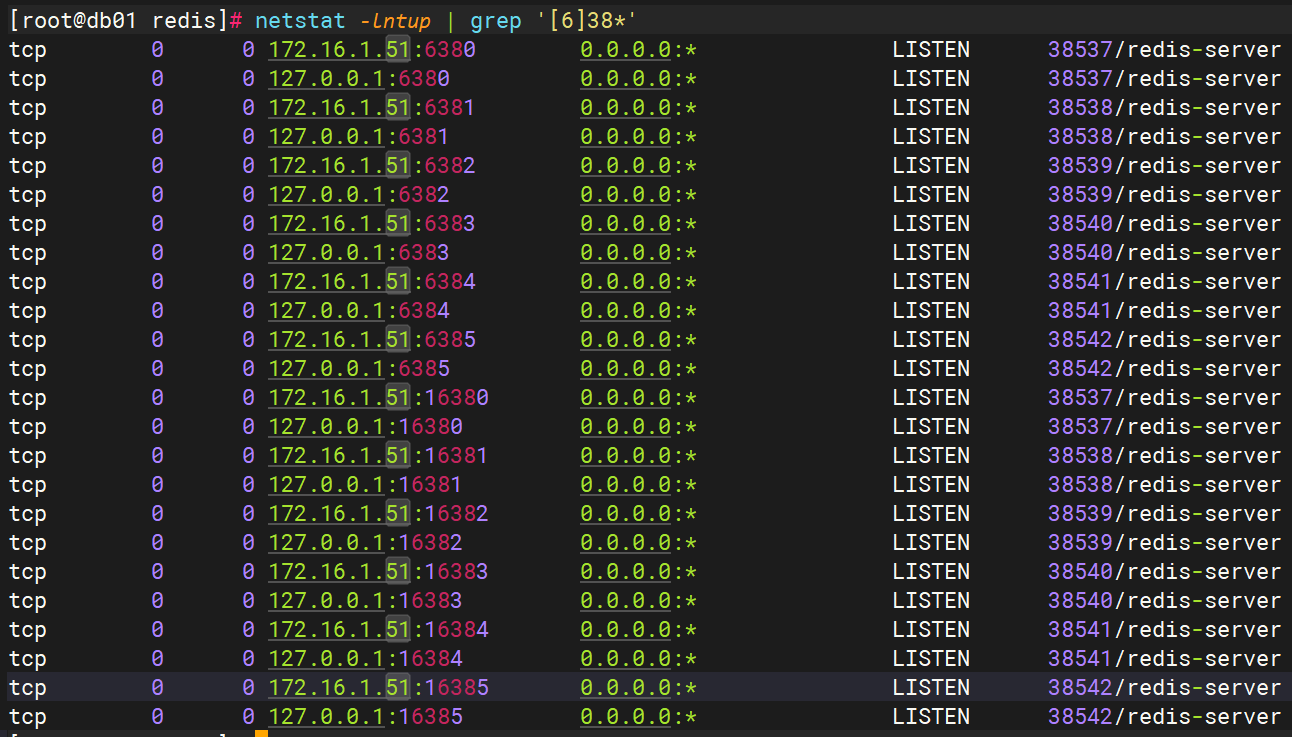
6.3、第二步 启动
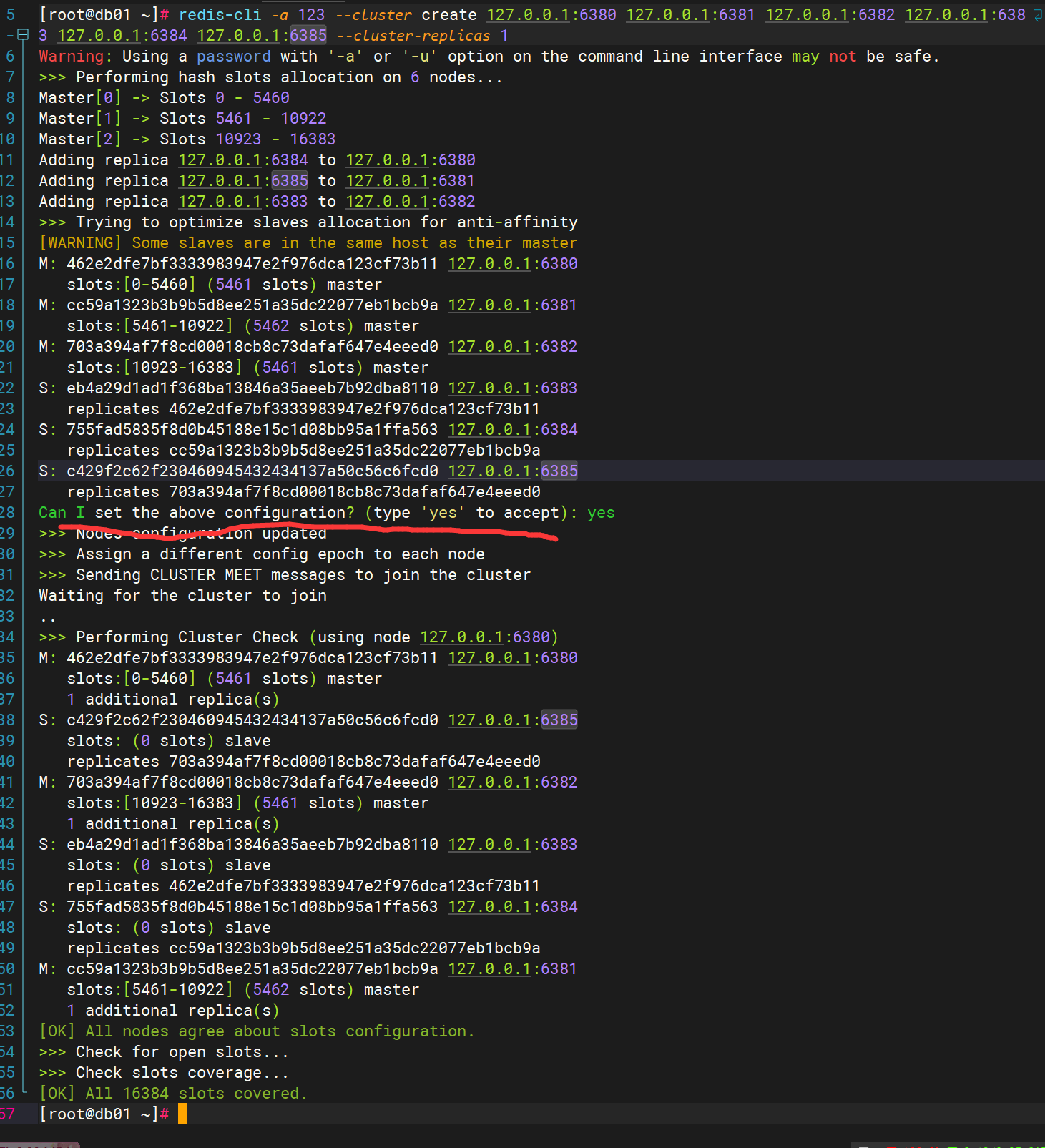
本人使用的redis是7.2版本,使用redis-cli启动集群
# host就是服务器的ip地址和端口,可以是多个
# --cluster-replicas指定主从结构主————从之间的比例,1就代表一个主下面必须有一个从,以此类推,6个服务器,那么前面三个就会成为master,后面三个依次会成为前面master的slave
语法:redis-cli --cluster create host[ host] --cluster-replicas 1
redis-cli -a 123 --cluster create 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384 127.0.0.1:6385 --cluster-replicas 1
启动完成就会出现如下界面:
6.3、node的配置文件
启动服务器后,会产生配置文件,集群一旦启动配置文件里面就会有其它节点的信息
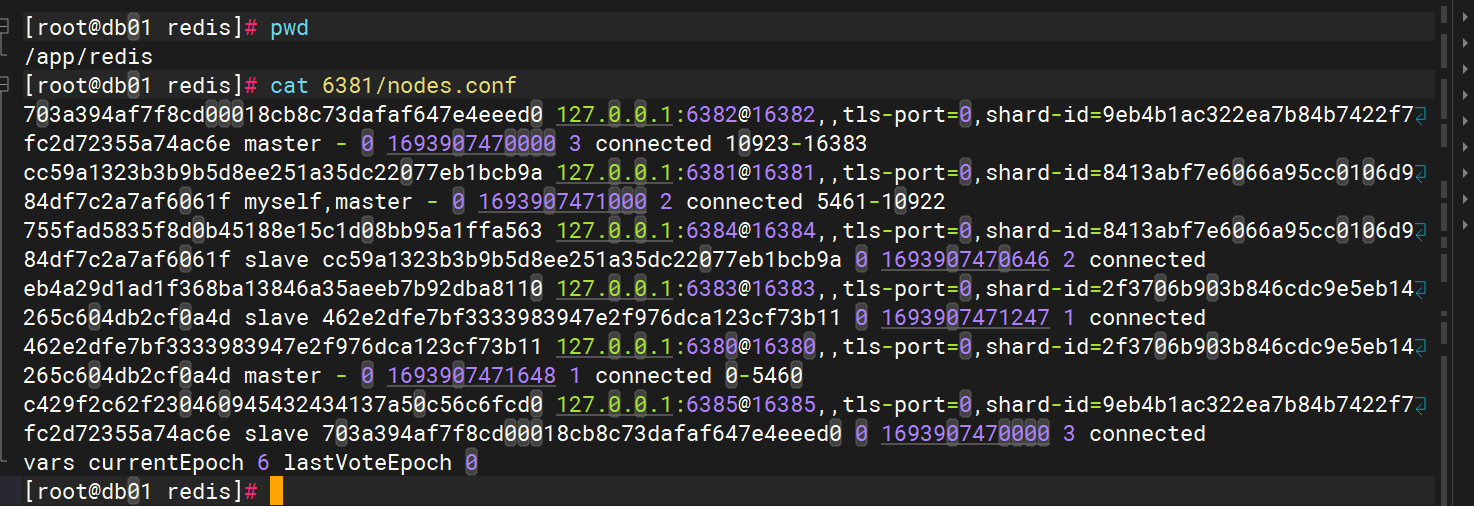
配置文件里面会记录哪些节点管理哪些槽区,和各个服务器之间的主从关系
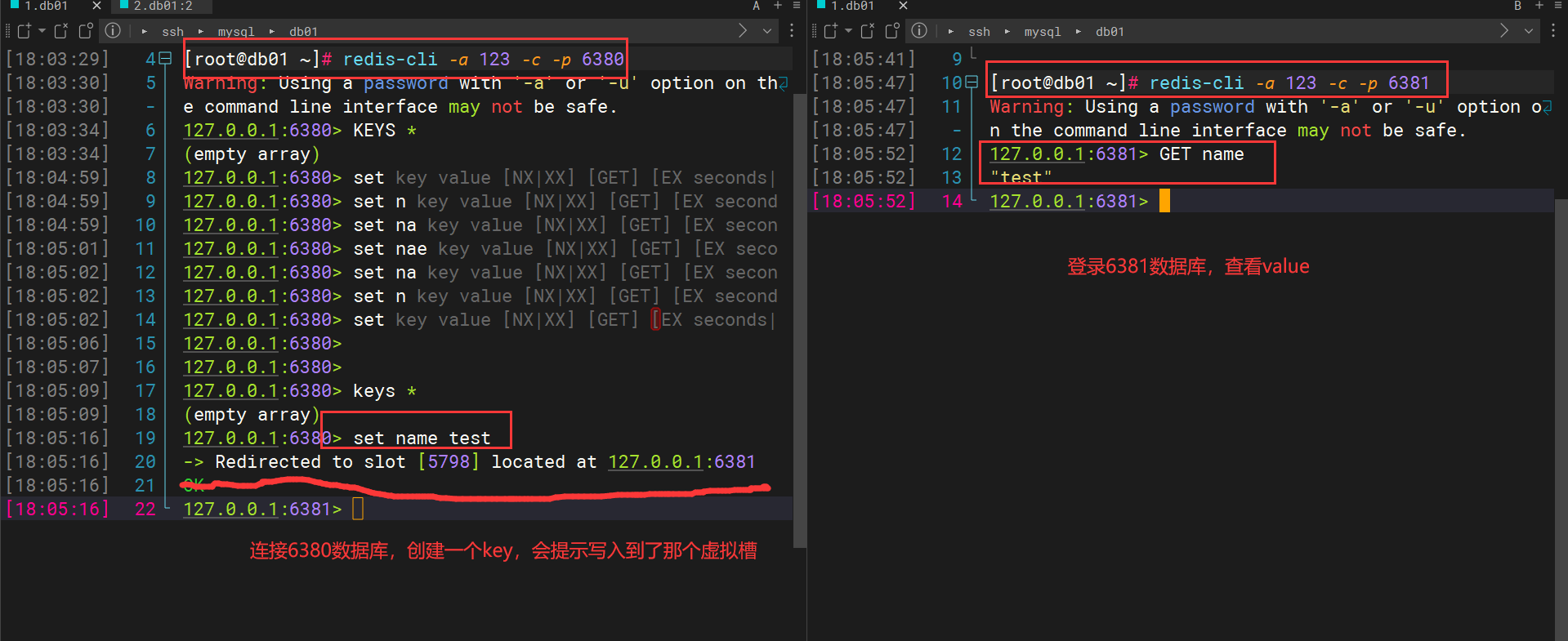
6.4、测试
通常我们都是用redis-cli程序获取和设置数据,但是使用集群后操作就会有稍稍的不一样,我们在连接服务器的时候,需要指定-c参数
# -c 参数就代表连接cluster里面的node
# -c 就代表我们连接的是集群(集群可以看做是一个大的虚拟redis程序)
redis-cli -c -p [port]