





环境准备:
| 主机名 | 外网IP | 内网IP | 环境 |
|---|---|---|---|
| lb01 | 172.16.1.5 | 10.0.0.5 | nginx |
| web01 | 172.16.1.7 | 10.0.0.7 | nginx |
| web02 | 172.16.1.8 | 10.0.0.8 | nginx |
web01部署nginx:
#关闭防火墙
systemctl stop firewalld
#下载nginx
yum install -y nginx
#编写配置文件
[root@web01 conf.d]# vim node.conf
server {
listen 80;
server_name jiujiu.com;
location / {
root /node;
index index.html;
}
}
#创建同名目录
mkdir /node
#追写内容
echo "hello,world" >/node/index.html
#重启nginx
systemctl restart nginxweb02部署同web01,只是修改追写内容为如下:
echo "hello,jiujiu" >/node/index.html
lb01部署:
#关闭防火墙
systemctl stop firewalld
#下载nginx
yum install -y nginx
#编写配置文件
[root@lb01 conf.d]# vim node_proxy.conf
upstream jiujiu {
server 172.16.1.7:80;
server 172.16.1.8:80;
}
server {
listen 80;
server_name jiujiu.com;
location / {
proxy_pass http://jiujiu;
include proxy_params;
}
}
#准备Nginx负载均衡调度使用的proxy_params
[root@lb01 conf.d]# vim /etc/nginx/proxy_params
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_connect_timeout 30;
proxy_send_timeout 60;
proxy_read_timeout 60;
proxy_buffering on;
proxy_buffer_size 32k;
proxy_buffers 4 128k;
#重启nginx
systemctl restart nginx
#本地域名解析
10.0.0.5 jiujiu.com
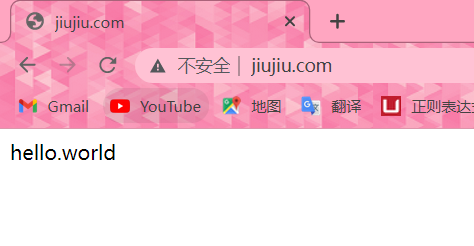
#浏览器访问,一直重复刷新出现如下两个页面表示成功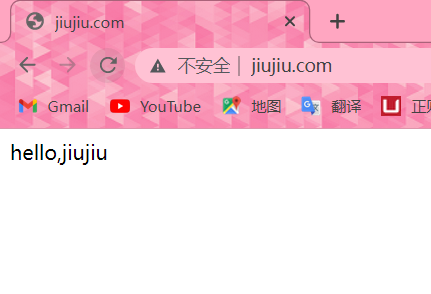
负载均衡常见典型故障
如果后台服务连接超时,Nginx是本身是有机制的,如果出现一个节点down掉的时候,Nginx会更据你具体负载均衡的设置,将请求转移到其他的节点上,但是,如果后台服务连接没有down掉,但是返回错误异常码了如:504、502、500,这个时候你需要加一个负载均衡的设置,如下:proxy_next_upstream http_500 | http_502 | http_503 | http_504 |http_404;意思是,当其中一台返回错误码404,500...等错误时,可以分配到下一台服务器程序继续处理,提高平台访问成功率。
upstream jiujiu {
server 172.16.1.7:80;
server 172.16.1.8:80;
}
server {
listen 80;
server_name jiujiu.com;
location / {
proxy_pass http://jiujiu;
proxy_next_upstream error timeout http_500 http_502 http_503 http_504;
}
}Nginx负载均衡调度算法
1、轮询(默认)每个请求按时间顺序逐一分配到不同的后端服务,如果后端某台服务器死机,自动剔除故障系统,使用户访问不受影响。
2、weight(轮询权值)weight的值越大分配到的访问概率越高,主要用于后端每台服务器性能不均衡的情况下。或者仅仅为在主从的情况下设置不同的权值,达到合理有效的地利用主机资源。
3、ip_hash源地址哈希法源地址哈希的思想是根据获取客户端的IP地址,通过哈希函数计算得到的一个数值,用该数值对服务器列表的大小进行取模运算,得到的结果便是客服端要访问服务器的序号。采用源地址哈希法进行负载均衡,同一IP地址的客户端,当后端服务器列表不变时,它每次都会映射到同一台后端服务器进行访问。
4、fair比 weight、ip_hash更加智能的负载均衡算法,fair算法可以根据页面大小和加载时间长短智能地进行负载均衡,也就是根据后端服务器的响应时间 来分配请求,响应时间短的优先分配。Nginx本身不支持fair,如果需要这种调度算法,则必须安装upstream_fair模块。
5、url_hash按访问的URL的哈希结果来分配请求,使每个URL定向到一台后端服务器,可以进一步提高后端缓存服务器的效率。Nginx本身不支持url_hash,如果需要这种调度算法,则必须安装Nginx的hash软件包。- 实践
1丶轮询
upstream test_load_balance {
# 默认是按轮询方式进行分配访问哪台服务器
server 10.0.0.201:80;
server 10.0.0.202:80;
}2丶weight 加权轮询
upstream test_load_balance {
# 按 weithe 方式分配
# 201这台服务器访问5次,202访问1次
server 10.0.0.201:80 weight=5;
server 10.0.0.202:80 weight=1;
}3丶ip_hash
不能和 weitht 加权轮询一起使用。
ip_hash 能解决会话登录的问题,但会造成负载的不均衡,导致某一台主机流量过大,其他主机没什么流量
upstream test_load_balance {
# ip_hash 方式访问
ip_hash;
server 10.0.0.201:80;
server 10.0.0.202:80;
}4丶url_hash
upstream test_load_balance {
# url_hash 方式
server 10.0.0.201:80;
server 10.0.0.202:80;
hash $request_uri;
}6、least_conn 最少链接数
upstream test_load_balance {
# least_conn 最少链接数方式
least_conn;
server 10.0.0.201:80;
server 10.0.0.202:80;
}、Nginx负载均衡调度状态
在Nginx upstream模块中,可以设定每台后端服务器在负载均衡调度中的状态,常用的状态有:
1、down,表示当前的server暂时不参与负载均衡
2、backup,预留的备份机器。当其他所有的非backup机器出现故障或者忙的时候,才会请求backup机器,因此这台机器的访问压力最低
3、max_fails,允许请求失败的次数,默认为1,当超过最大次数时,返回proxy_next_upstream模块定义的错误。
4、fail_timeout,请求失败超时时间,在经历了max_fails次失败后,暂停服务的时间。max_fails和fail_timeout可以一起使用。
如果Nginx没有仅仅只能代理一台服务器的话,那它也不可能像今天这么火,Nginx可以配置代理多台服务器,当一台服务器宕机之后,仍能保持系统可用。具体配置过程如下:
----------------------------------------------------------------------------------------------------
1. 在http节点下,添加upstream节点。
upstream linuxidc {
server 10.0.6.108:7080;
server 10.0.0.85:8980;
}
2. 将server节点下的location节点中的proxy_pass配置为:http:// + upstream名称,即“http://linuxidc”.
location / {
root html; index index.html index.htm;
proxy_pass http://linuxidc;
}
3. 现在负载均衡初步完成了。upstream按照轮询(默认)方式进行负载,每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。虽然这种方式简便、成本低廉。但缺点是:可靠性低和负载分配不均衡。适用于图片服务器集群和纯静态页面服务器集群。
除此之外,upstream还有其它的分配策略,分别如下:
weight(权重)
指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。如下所示,10.0.0.88的访问比率要比10.0.0.77的访问比率高一倍。
upstream linuxidc {
server 10.0.0.77 weight=5;
server 10.0.0.88 weight=10;
}
# ip_hash(访问ip)
每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。
upstream favresin {
ip_hash;
server 10.0.0.10:8080;
server 10.0.0.11:8080;
}
# fair(第三方)
按后端服务器的响应时间来分配请求,响应时间短的优先分配。与weight分配策略类似。
upstream favresin {
server 10.0.0.10:8080;
server 10.0.0.11:8080; fair;
}
# url_hash(第三方)
按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,后端服务器为缓存时比较有效。
注意:在upstream中加入hash语句,server语句中不能写入weight等其他的参数,hash_method是使用的hash算法。
upstream resinserver {
server 10.0.0.10:7777;
server 10.0.0.11:8888;
hash $request_uri;
hash_method crc32;
}
upstream还可以为每个设备设置状态值,这些状态值的含义分别如下:
down 表示单前的server暂时不参与负载.
weight 默认为1.weight越大,负载的权重就越大。
max_fails :允许请求失败的次数默认为1.当超过最大次数时,返回proxy_next_upstream 模块定义的错误.
fail_timeout : max_fails次失败后,暂停的时间。
backup: 其它所有的非backup机器down或者忙的时候,请求backup机器。所以这台机器压力会最轻。
upstream bakend { #定义负载均衡设备的Ip及设备状态
ip_hash;
server 10.0.0.11:9090 down;
server 10.0.0.11:8080 weight=2;
server 10.0.0.11:6060;
server 10.0.0.11:7070 backup;
}
