





ELK介绍
什么是ELK?
通俗来讲,ELK是由Elasticsearch、Logstash、Kibana 三个开源软件的组成的一个组合体,这三个软件当中,每个软件用于完成不同的功能,ELK 又称为ELK stack,官方域名为elastic.co,ELK stack的主要优点有如下几个:
1.处理方式灵活: elasticsearch是实时全文索引,具有强大的搜索功能
2.配置相对简单:elasticsearch全部使用JSON 接口,logstash使用模块配置,kibana的配置文件部分更简单。
3.检索性能高效:基于优秀的设计,虽然每次查询都是实时,但是也可以达到百亿级数据的查询秒级响应。
4.集群线性扩展:elasticsearch和logstash都可以灵活线性扩展
5.前端操作绚丽:kibana的前端设计比较绚丽,而且操作简单
什么是Elasticsearch?
是一个高度可扩展的开源全文搜索和分析引擎,它可实现数据的实时全文搜索搜索、支持分布式可实现高可用、提供API接口,可以处理大规模日志数据,比如Nginx、Tomcat、系统日志等功能。
什么是Logstash?
可以通过插件实现日志收集和转发,支持日志过滤,支持普通log、自定义json格式的日志解析。可以通俗的说做跑腿工作的
什么是Kibana?
主要是通过接口调用elasticsearch的数据,并进行前端数据可视化的展现。
为什么使用ELK?
专门做日志收集的集群
日志收集?
提供一个web页面
实际部署Elasticsearch
环境准备:
| 主机名 | 外网IP | 内网IP | 角色 | 应用 |
|---|---|---|---|---|
| web01 | 10.0.0.7 | 172.16.1.7 | els日志存储数据库,主节点1 | JDK,elasticsearch |
| web02 | 10.0.0.8 | 172.16.1.8 | els日志存储数据库,节点2 | JDK,elasticsearch |
# 安装JDK
yum install -y java
## 更换ES官方源
[root@web01 ~]# vim /etc/yum.repos.d/es.repo
[elasticsearch-5.x]
name=Elasticsearch repository for 5.x packages
baseurl=https://artifacts.elastic.co/packages/5.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
# 下载es
yum install -y elasticsearch
# 配置es的配置文件
[root@web01 ~]# vim /etc/elasticsearch/elasticsearch.yml
17 cluster.name: elkstack #//集群的名称
23 node.name: es01 #//节点名称
33 path.data: /data/es/data #//数据储存路径
37 path.logs: /data/es/logs #//日志存放路径
43 bootstrap.memory_lock: true #//如果服务起不来就改false
55 network.host: 0.0.0.0 #//允许访问的网段
59 http.port: 9200 #//启动端口
68 discovery.zen.ping.unicast.hosts: ["10.0.0.81", "10.0.0.82"] #//节点发现和通信的主机列表
[root@web01 ~]# grep '^[a-z]' /etc/elasticsearch/elasticsearch.yml
cluster.name: elkstack
node.name: es01
path.data: /data/es/data
path.logs: /data/es/logs
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["10.0.0.7", "10.0.0.8"]
# 创建日志和数据存放目录
[root@elk01 ~]# mkdir -p /data/es/{data,logs}
# 修改启动脚本
[root@web01 ~]# vim /usr/lib/systemd/system/elasticsearch.service
# 修改内存限制(去掉此行注释)//如果没有跳过即可
LimitMEMLOCK=infinity
# 授权
[root@web01 ~]# chown -R elasticsearch.elasticsearch /data/
[root@web01 ~]# ll -d /data/
drwxr-xr-x 3 elasticsearch elasticsearch 16 Jul 10 14:25 /data/
# 优化文件描述符 //文件末尾加入即可
[root@web01 ~]# vim /etc/security/limits.conf
* soft memlock unlimited
* hard memlock unlimited
* soft nofile 131072
* hard nofile 131072
# 设置JVM最大最小内存限制 22行和23行处
[root@web01 ~]# vim /etc/elasticsearch/jvm.options
-Xms1g
-Xmx1g
# 启动es
[root@web02 ~]# systemctl start elasticsearch
[root@web01 ~]# netstat -lntup
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN 6035/rpcbind
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 6912/sshd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 7045/master
tcp6 0 0 :::111 :::* LISTEN 6035/rpcbind
tcp6 0 0 :::9200 :::* LISTEN 7503/java
tcp6 0 0 :::9300 :::* LISTEN 7503/java
tcp6 0 0 :::22 :::* LISTEN 6912/sshd
tcp6 0 0 ::1:25 :::* LISTEN 7045/master
udp 0 0 0.0.0.0:111 0.0.0.0:* 6035/rpcbind
udp 0 0 0.0.0.0:663 0.0.0.0:* 6035/rpcbind
udp6 0 0 :::111 :::* 6035/rpcbind
udp6 0 0 :::663 :::* 6035/rpcbind
#//启动时间较长,耐心等待即可;超过一定时间可以采取如下方法: 43行左右,第二行需手动添加
[root@web01 ~]# vim /etc/elasticsearch/elasticsearch.yml
bootstrap.memory_lock: false #//是否将堆内存锁定在物理内存中
bootstrap.system_call_filter: false #//控制 Elasticsearch 在启动过程中是否使用系统级调用过滤器
# 浏览器访问 web02重复web01操作即可
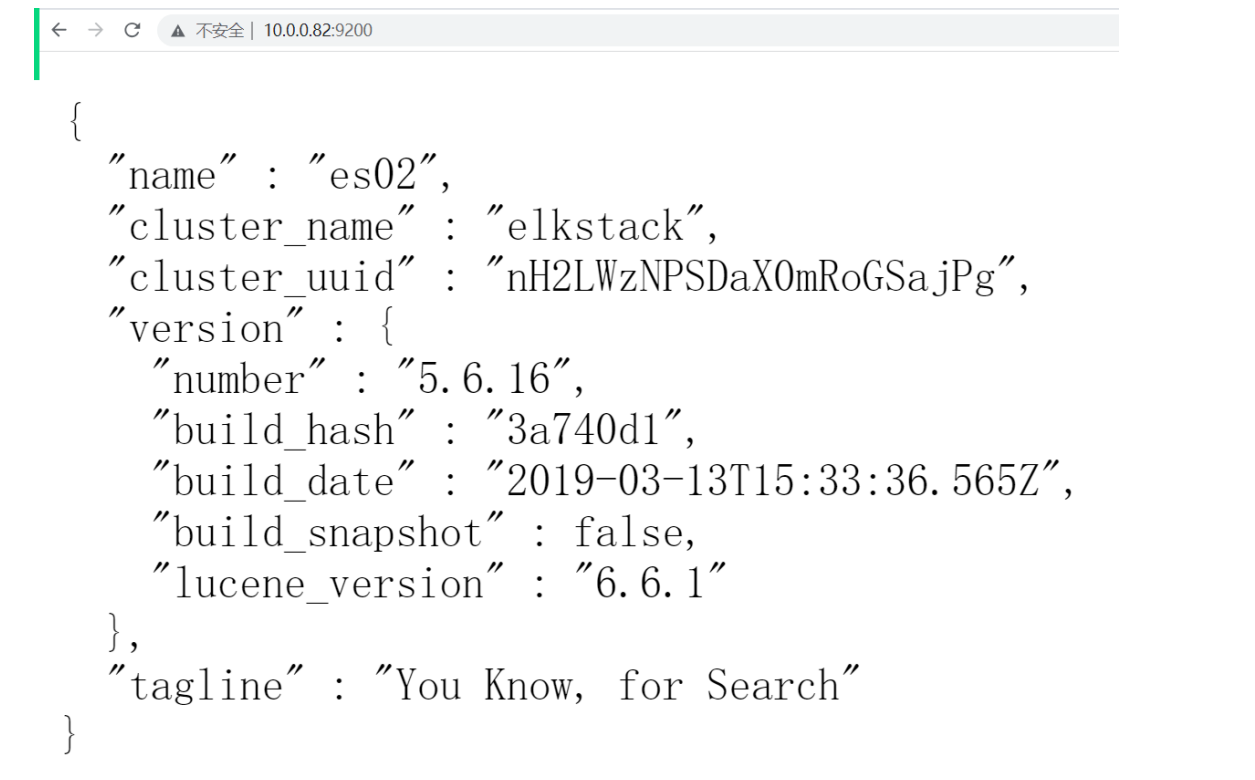
10.0.0.7:9200
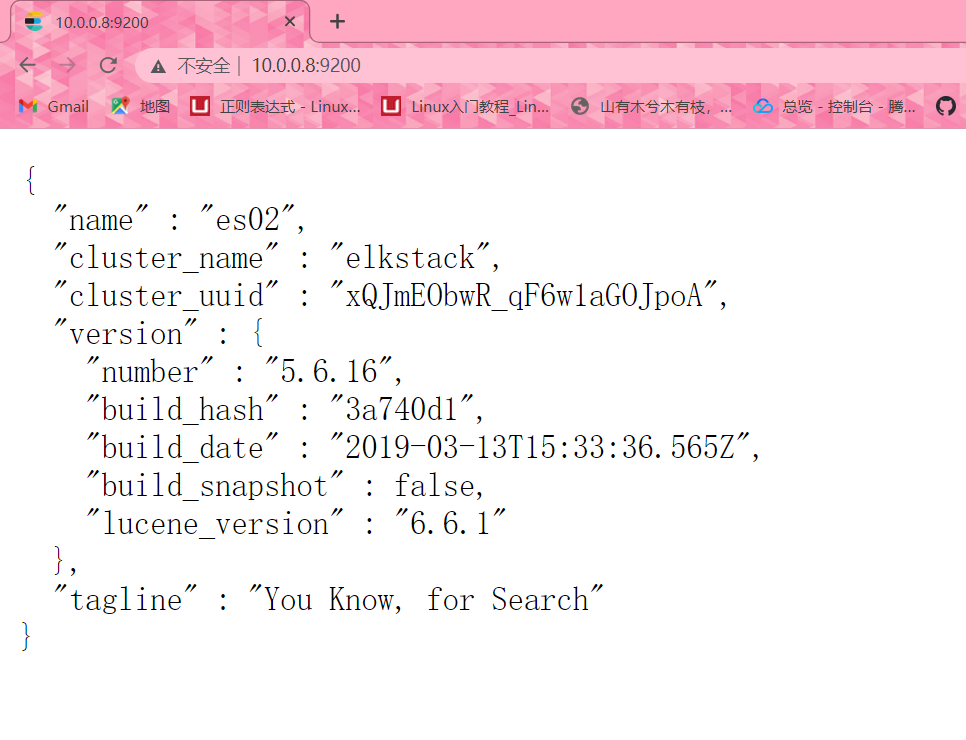
10.0.0.8:9200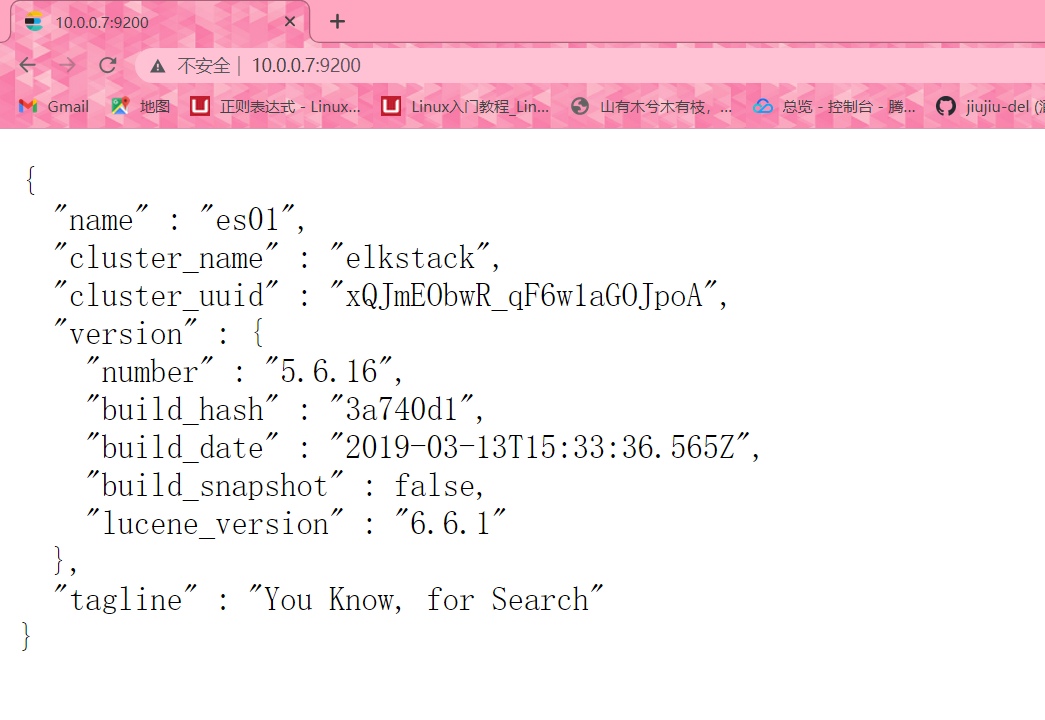
实现可视化Elasticsearch插件/web01安裝即可
插件是为了完成不同的功能,官方提供了一些插件但大部分是收费的,另外也有一些开发爱好者提供的
插件,可以实现对elasticsearch集群的状态监控与管理配置等功能,我们现在要安装的是Elasticsearch
的head插件,此插件提供elasticsearch的web界面功能。
安装Elasticsearch的head插件时,要安装npm,npm的全称是Node Package Manager,是随同
NodeJS一起安装的包管理和分发工具,它很方便让JavaScript开发者下载、安装、上传以及管理已经安
装的包。
在Elasticsearch 5.x版本以后不再支持直接安装head插件,而是需要通过启动一个服务方式。
Github地址:https://github.com/mobz/elasticsearch-head
# 安装npm
[root@web01 ~]# yum install -y npm
# 安装git命令
[root@web01 ~]# yum install -y git
## 下载head插件
[root@elk01 ~]# git clone https://github.com/mobz/elasticsearch-head.git
Cloning into 'elasticsearch-head'...
remote: Enumerating objects: 4377, done.
remote: Counting objects: 100% (40/40), done.
remote: Compressing objects: 100% (27/27), done.
remote: Total 4377 (delta 12), reused 34 (delta 12), pack-reused 4337
Receiving objects: 100% (4377/4377), 2.54 MiB | 2.15 MiB/s, done.
Resolving deltas: 100% (2429/2429), done.
## 下载nodejs
[root@web01 ~]# wget https://nodejs.org/dist/v16.13.0/node-v16.13.0-linux-x64.tar.xz
## 解压nodejs
[root@web01 ~]# tar xf node-v16.13.0-linux-x64.tar.xz
[root@web01 ~]# mkdir /app
[root@web01 ~]# mv node-v16.13.0-linux-x64 /app/
# 做软连接
[root@web01 ~]# ln -s /app/node-v16.13.0-linux-x64/ /app/node
# 添加环境变量
[root@web01 ~]# vim /etc/profile.d/node.sh
export PATH="/app/node/bin:$PATH"
# 生效配置文件
[root@web01 ~]# source /etc/profile
PATH=/app/node/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
# 查看版本
[root@elk01 ~]# npm --version
8.19.2
# 进入head插件目录
[root@web01 ~]# cd /root/elasticsearch-head
# 换源
npm config set registry=https://registry.npm.taobao.org
# 查看当前包下的镜像源
[root@elk01 elasticsearch-head]# npm config get registry
https://registry.npm.taobao.org/
# 安装还原命令
[root@elk01 elasticsearch-head]# npm install -g nrm open@8.4.2 --save
added 17 packages in 6s
npm notice
npm notice New major version of npm available! 8.19.2 -> 9.8.0
npm notice Changelog: https://github.com/npm/cli/releases/tag/v9.8.0
npm notice Run npm install -g npm@9.8.0 to update!
npm notice
# 查看可用源
[root@elk01 elasticsearch-head]# nrm ls
npm ---------- https://registry.npmjs.org/
yarn --------- https://registry.yarnpkg.com/
tencent ------ https://mirrors.cloud.tencent.com/npm/
cnpm --------- https://r.cnpmjs.org/
taobao ------- https://registry.npmmirror.com/
npmMirror ---- https://skimdb.npmjs.com/registry/
# 切换到taobao源
[root@web01 elasticsearch-head]# nrm use taobao
SUCCESS The registry has been changed to 'taobao'.
## 保存phantomjs-2.1.1-linux-x86_64.tar.bz2 到/root
#下载解压命令
[root@web01 ~]# yum install -y bzip2
#解压phantomjs-2.1.1-linux-x86_64.tar.bz2
[root@web01 ~]# tar -xf phantomjs-2.1.1-linux-x86_64.tar.bz2
# 进入目录
[root@web01 ~]# cd /root/phantomjs-2.1.1-linux-x86_64
[root@web01 phantomjs-2.1.1-linux-x86_64]# cp bin/phantomjs /usr/local/bin/
# 回到elasticsearch-head
[root@web01 phantomjs-2.1.1-linux-x86_64]# cd /root/elasticsearch-head
# 安装
[root@web01 elasticsearch-head]# npm install grunt -save-no-fund
# 启动head插件
[root@web01 elasticsearch-head]# npm run start &
[1] 18164
[root@web01 elasticsearch-head]#
> elasticsearch-head@0.0.0 start
> grunt server
Running "connect:server" (connect) task
Waiting forever...
Started connect web server on http://localhost:9100
# 检查插件
[root@web01 ~]# netstat -lntup
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:9100 0.0.0.0:* LISTEN 8398/grunt
# 访问浏览器
10.0.0.7:9100
#这个时候如果修改localhost为节主机IP的话,那么还是无法连接到,需开启如下功能:
# 开启跨域访问支持 //文本末尾添加即可
[root@web01 ~]# vim /etc/elasticsearch/elasticsearch.ym
http.cors.enabled: true
http.cors.allow-origin: "*"
# 重启elasticsearch
systemctl restart elasticsearch.service
#星号为主节点服务器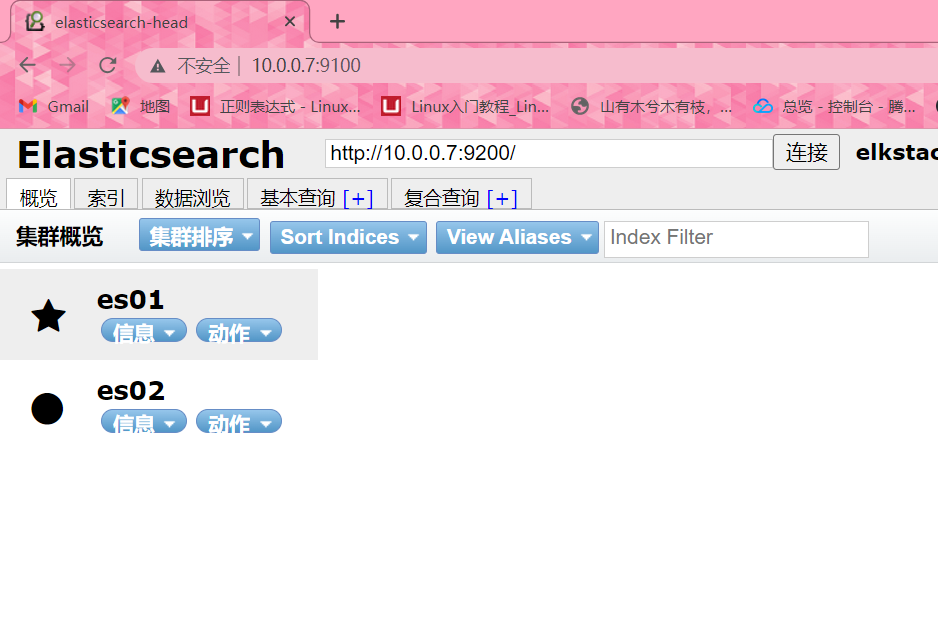
Elasticsearch副本生片
什么是副本分片?
1、副本分片的主要目的就是为了故障转移,如果持有主分片的节点挂掉了,一个副本分片就会晋升为主分片的角色。
2、在索引写入时,副本分片做着与主分片相同的工作。新文档首先被索引进主分片然后再同步到其它所有的副本分片。增加副本数并不会增加索引容量。
3、无论如何,副本分片可以服务于读请求,如果你的索引也如常见的那样是偏向查询使用的,那你可以通过增加副本的数目来提升查询性能,但也要为此,增加额外的硬件资源。Elasticsearch内部分片处理机制
#逆向索引
与传统的数据库不同,在Elasticsearch中,每个字段里面的每个单词都是可以被搜索的。如teacher:“zls,bgx,lidao,oldboy,alex”我们在搜索关键字oldboy时,所有包含oldboy的文档都会被匹配到Elasticsearch的这个特性也叫做全文搜索。
为了支持这个特性,Elasticsearch中会维护一个叫做“invertedindex”(也叫逆向索引)的表,表内包含了所有文档中出现的所有单词,同时记录了这个单词在哪个文档中出现过。
例:
当前有4个文档
txt1:“zls,bgx,lidao”
txt2:“zls,oldboy,alex”
txt3:“bgx,lidao,oldboy”
txt4:“oldboy,alex”
那么Elasticsearch会维护下面一个数据结构表:| Term | txt1 | txt2 | txt3 | txt4 |
|---|---|---|---|---|
| zls | Y | Y | ||
| bgx | Y | Y | ||
| lidao | Y | Y | ||
| oldbay | Y | Y | Y | |
| alex | Y | Y |
随意搜索任意一个单词,Elasticsearch只要遍历一下这个表,就可以知道有些文档被匹配到了。逆向索引里面不止记录了单词与文档的对应关系,它还维护了很多其他有用的数据。如:每个文档一共包含了多少个单词,单词在不同文档中的出现频率,每个文档的长度,所有文档的总长度等等。这些数据用来给搜索结果进行打分,如搜索zls时,那么出现zls这个单词次数最多的文档会被优先返回,因为它匹配的次数最多,和我们的搜索条件关联性最大,因此得分也最多。
逆向索引是不可更改的,一旦它被建立了,里面的数据就不会再进行更改。这样做就带来了以下几个好处:
1.没有必要给逆向索引加锁,因为不允许被更改,只有读操作,所以就不用考虑多线程导致互斥等
问题。
2.索引一旦被加载到了缓存中,大部分访问操作都是对内存的读操作,省去了访问磁盘带来的io开
销。
3.因为逆向索引的不可变性,所有基于该索引而产生的缓存也不需要更改,因为没有数据变更。
4.使用逆向索引可以压缩数据,减少磁盘io及对内存的消耗。Segment
既然逆向索引是不可更改的,那么如何添加新的数据,删除数据以及更新数据?为了解决这个问题,
lucene将一个大的逆向索引拆分成了多个小的段segment。每个segment本质上就是一个逆向索引。在
lucene中,同时还会维护一个文件commit point,用来记录当前所有可用的segment,当我们在这个
commit point上进行搜索时,就相当于在它下面的segment中进行搜索,每个segment返回自己的搜索
结果,然后进行汇总返回给用户。
引入了segment和commit point的概念之后,数据的更新流程如下图: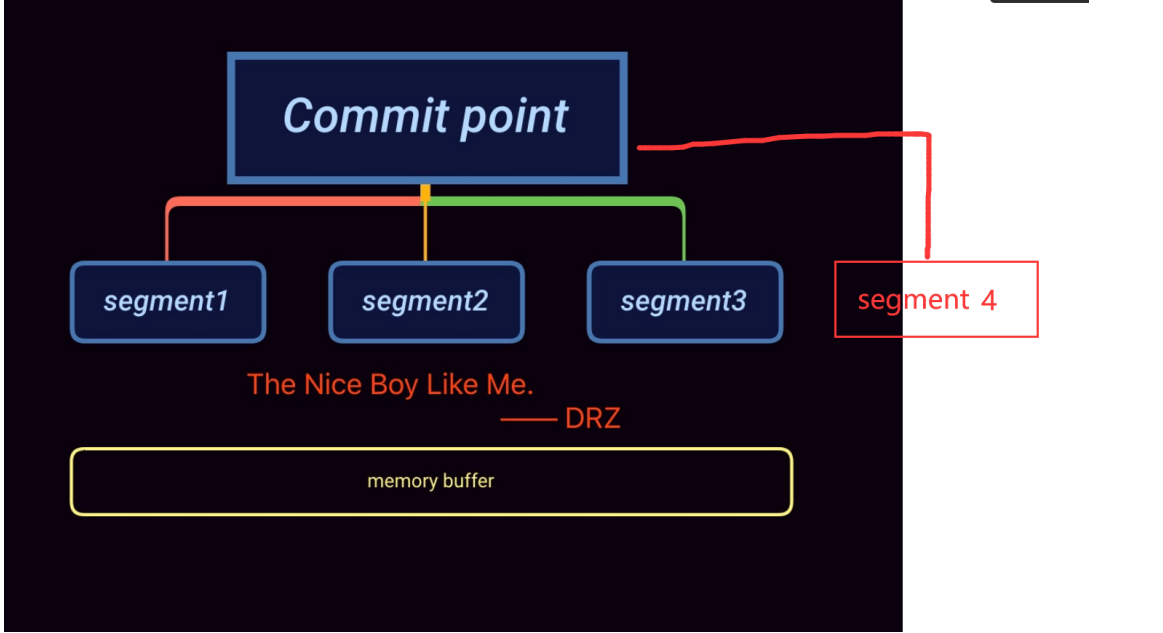
-
1.新增的文档首先会被存放在内存的缓存中
-
2.当文档数足够多或者到达一定时间点时,就会对缓存进行commit
- a. 生成一个新的segment,并写入磁盘
- b. 生成一个新的commit point,记录当前所有可用的segment
- c. 等待所有数据都已写入磁盘
-
3.打开新增的segment,这样我们就可以对新增的文档进行搜索了
-
4.清空缓存,准备接收新的文档
为什么要考虑副本分片数量?
#大多数ElasticSearch用户在创建索引时通用会考虑一个重要问题是:我需要创建多少个分片?
1、分片分配是个很重要的概念, 很多用户对如何分片都有所疑惑, 当然是为了让分配更合理. 在生产环境中,随着数据集的增长, 不合理的分配策略可能会给系统的扩展带来严重的问题。同时, 这方面的文档介绍也非常少。很多用户只想要明确的答案而不仅仅一个数字范围, 甚至都不关心随意的设置可能带来的问题。
2、首先,我们需要了解ES中以下几个名词,是做什么的:
#集群(cluster):
由一个或多个节点组成, 并通过集群名称与其他集群进行区分
#节点(node):
单个ElasticSearch实例. 通常一个节点运行在一个隔离的容器或虚拟机中
#索引(index):
在ES中, 索引是一组文档的集合(就是我们所说的一个日志)
#分片(shard):
因为ES是个分布式的搜索引擎, 所以索引通常都会分解成不同部分, 而这些分布在不同节点的数据就是分片. ES自动管理和组织分片, 并在必要的时候对分片数据进行再平衡分配, 所以用户基本上不用担心分片的处理细节,一个分片默认最大文档数量是20亿.
#副本(replica):ES默认为一个索引创建5个主分片, 并分别为其创建一个副本分片. 也就是说每个索引都由5个主分片成本, 而每个主分片都相应的有一个copy.对于分布式搜索引擎来说, 分片及副本的分配将是高可用及快速搜索响应的设计核心.主分片与副本都能处理查询请求, 它们的唯一区别在于只有主分片才能处理索引请求
谨慎分片
1、副本对搜索性能非常重要, 同时用户也可在任何时候添加或删除副本。额外的副本能给你带来更大的容量, 更高的呑吐能力及更强的故障恢复能力。
2、当在ElasticSearch集群中配置好你的索引后, 你要明白在集群运行中你无法调整分片设置。既便以后你发现需要调整分片数量, 你也只能新建创建并对数据进行重新索引(reindex)(虽然reindex会比较耗时, 但至少能保证你不会停机)。
3、主分片的配置与硬盘分区很类似, 在对一块空的硬盘空间进行分区时, 会要求用户先进行数据备份, 然后配
置新的分区, 最后把数据写到新的分区上。
4、在分片时,主要考虑数据集的增长趋势,一定要做到不要过度分片,并不是分片越多越好,从ES社区用户对这个热门主题(分片配置)的分享数据来看, 用户可能认为过度分配是个绝对安全的策略(这里讲的过度分配是指对特定数据集, 为每个索引分配了超出当前数据量(文档数)所需要的分片数)。稍有富余是好的, 但过度分配分片却是大错特错. 具体定义多少分片很难有定论, 取决于用户的数据量和使用方式. 100个分片, 即便很少使用也可能是好的;而2个分片, 即便使用非常频繁, 也可能是多
余的.
-----------------------------------------------------------------------------------------------------
我们要熟知以下几点内容:
1.每分配一个分片,都会有额外的成本。
2.每个分片本质上就是一个Lucene索引,因此会消耗相应的文件句柄,内存和CPU资源。
3.每个搜索请求会调度到索引的每个分片中。如果分片分散在不同的节点倒是问题不太。但当分片开始
竞争相同的硬件资源时,性能便会逐步下降。
4.ES使用词频统计来计算相关性。当然这些统计也会分配到各个分片上。如果在大量分片上只维护了很
少的数据,则将导致最终的文档相关性较差测试提交数据
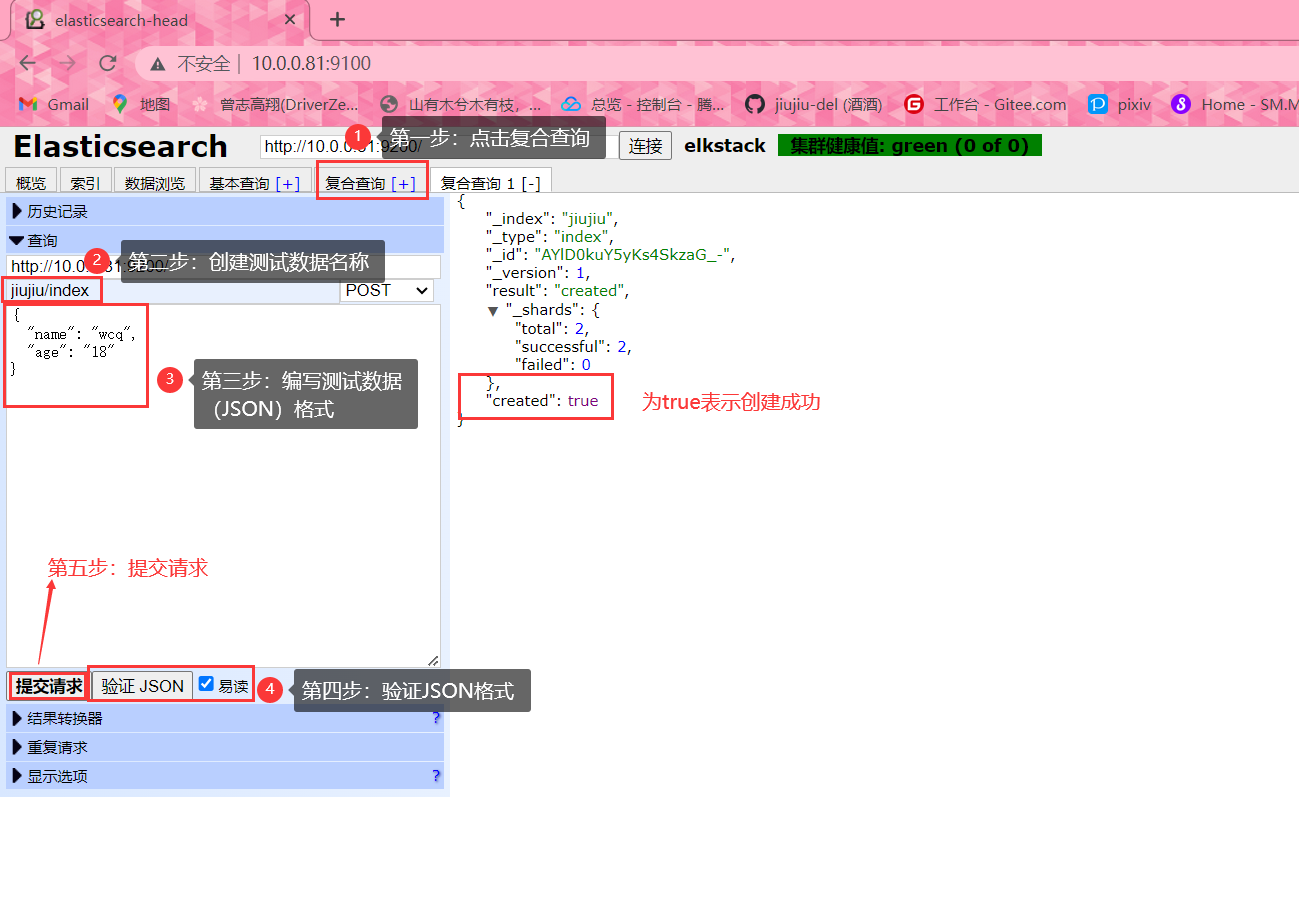
重启Elasticsearch服务
[root@elk01 elasticsearch-head]# systemctl restart elasticsearch.service 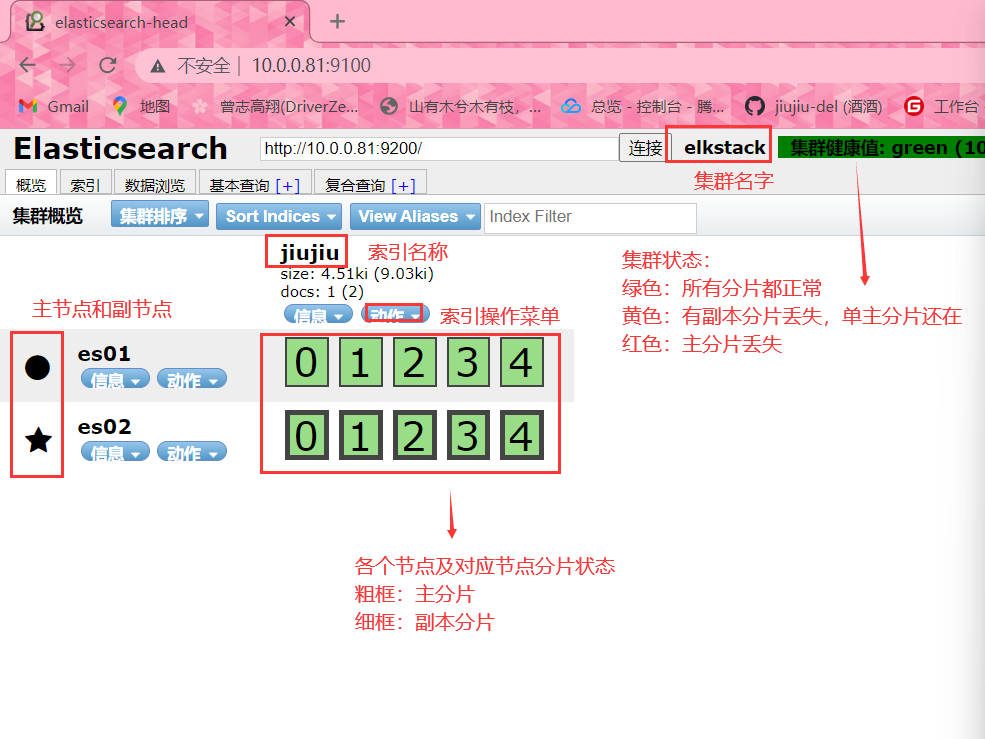
集群检测实战
在linux中,我们可以通过curl命令获取集群的状态
#编写检测脚本
[root@elk01 ~]# vim check.py
-----------------------------------------------------------------------------------------------------
#!/usr/bin/env python
#coding:utf-8
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr
import subprocess
body = ""
false = "false"
clusterip = "10.0.0.81"
obj = subprocess.Popen(("curl -sXGET http://"+clusterip+":9200/_cluster/health?pretty=true"),shell=True, stdout=subprocess.PIPE)
data = obj.stdout.read()
data1 = eval(data)
status = data1.get("status")
if status == "green":
print "\033[1;32m 集群运行正常 \033[0m"
elif status == "yellow":
print "\033[1;33m 副本分片丢失 \033[0m"
else:
print "\033[1;31m 主分片丢失 \033[0m"
-----------------------------------------------------------------------------------------------------
[root@elk01 ~]# python check.py
集群运行正常 
